집프의 법칙
Zipf's law

Zipf's law (/zɪf/, 독일어:[ts ͡ɪpf])는 측정값 목록이 감소하는 순서로 정렬될 때 종종 유지되는 경험적 법칙입니다. n번째 항목의 값은 n에 반비례한다고 명시되어 있습니다.
Zipf 법칙의 가장 잘 알려진 예는 자연어의 텍스트 또는 말뭉치의 단어 빈도표에 적용됩니다.


이 "법칙"은 미국의 언어학자 조지 킹슬리 집프의 이름을 따서 지어졌고,[3][4][5] 여전히 양적 언어학에서 중요한 개념입니다. 이는 물리학 및 사회 과학에서 연구되는 다른 많은 유형의 데이터에 적용되는 것으로 나타났습니다.
수학 통계학에서 이 개념은 순위-주파수 분포가 역제곱 법칙 관계인 관련 이산 확률 분포의 계열인 Zipfian 분포로 공식화되었습니다. 그들은 벤포드 법칙과 파레토 분포와 관련이 있습니다.
일부 시간 의존적인 경험적 데이터 세트는 Zipf의 법칙에서 다소 벗어나 있습니다. 그러한 경험적 분포를 준집피안(quasi-Zipfian)이라고 합니다.
역사
1913년, 독일의 물리학자 펠릭스 아우어바흐는 도시의 인구 규모와 그 변수의 감소하는 순서로 정렬될 때 그 순위 사이에 반비례하는 것을 관찰했습니다.[6]
Zipf의 법칙은 1916년 프랑스의 속기사인 Jean-Baptiste Estoup' Gammes Stenographiques([7]제4판)가 G와 함께 [a]Zipf 이전에 발견했습니다. 1923년 듀이,[8] 1928년 E. 콘돈과 함께.[9]
1932년 조지 집프(George Zipf)는 자연어 텍스트에서 단어의 빈도에 대한 동일한 관계를 관찰했지만,[4] 그는 그것이 기원이라고 주장한 적이 없습니다. 사실 Zipf는 수학을 좋아하지 않았습니다. 1932년에 출판된 그의 책에서 [10]저자는 언어학에 수학적으로 관여하는 것을 경멸하는 태도로 말하고 있습니다. a. o. ibidem, p. 21: (…) 제 생각에, 어떤 수학자든, 다음의 데이터를 보다 정확하게 공식화할 계획을 갖고 있는 사람을 위해 여기서 말씀드리겠습니다. 매우 강렬한 긍정이 매우 강렬한 부정이 될 수 있는 능력입니다. 악마를 √(-i)의 형태로 공식에 도입합니다. 집프가 사용한 유일한 수학적 표현은 알프레드 J. 로트카의 1926년 출판물에서 "borrowed"한 a.b = 상수처럼 보입니다.
빈도 외에 다른 많은 맥락과 다른 변수에서도 동일한 관계가 발생하는 것으로 나타났습니다.[1] 예를 들어, 기업의 규모가 감소하여 순위가 매겨질 때 기업의 규모는 순위에 반비례하는 것으로 나타났습니다.[12] 개인 소득(파레토 원리라고[13] 함), 동일한 TV 채널을 시청하는 사람의 수,[14] 음악의 노트,[15] 세포 전사체[16][17] 등에서도 동일한 관계가 발견됩니다.
1992년 생물정보학자 웬티안 리(Wentian Li)는 무작위로 생성된 텍스트에서도 Zipf의 법칙이 나타난다는 짧은[18] 논문을 발표했습니다. 집프의 법칙의 거듭제곱 법칙 형태가 계급별로 단어를 순서화한 부산물이라는 증거가 포함되어 있었습니다.
형식적 정의
| 확률질량함수  로그-로그 스케일에서 N = 10에 대한 Zipf PMF. 가로축은 인덱스 k입니다.(함수는 k의 정수 값에서만 정의됩니다. 연결선은 연속성을 나타내지 않습니다.) | |||
| 누적분포함수  Zipf CDF for N = 10. 가로축은 인덱스 k입니다.(함수는 k의 정수 값에서만 정의됩니다. 연결선은 연속성을 나타내지 않습니다.) | |||
| 매개변수 | 0 geq 0\,} (실제) {,2 …} \{1,2,3ldots \}} (정수) | ||
|---|---|---|---|
| 지지하다 | |||
| PMF | 여기서 H는N,s N번째 일반화 고조파 수이다. | ||
| CDF | |||
| 의미하다 | |||
| 모드 | |||
| 분산 | |||
| 엔트로피 | |||
| MGF | |||
| CF | |||









공식적으로, N개의 원소에 대한 Zipf 분포는 (1부터 계산) 순위 k의 원소에 확률을 할당합니다.

여기서 H는N 정규화 상수, N차 고조파 수:

분포는 1이 아닌 지수를 갖는 역제곱 법칙으로 일반화되기도 합니다.[19] 즉,

여기서 H는N,s 일반화된 조화수

일반화된 Zipf 분포는 지수가 1을 초과하는 경우에만 무한히 많은 항목(N = ∞)으로 확장될 수 있습니다. 이 경우, 정규화 상수N,s H는 리만의 제타 함수가 되며,

지수 s가 1 이하이면 N이 무한대로 갈수록 정규화 상수 H가N,s 발산합니다.
경험적 테스트
경험적으로, 콜모고로프-스미르노프 검정으로 가설된 멱법칙 분포에 대한 경험적 분포의 적합도를 확인함으로써 Zipf의 법칙이 적용되는지 여부를 확인하기 위해 데이터 세트를 검정할 수 있습니다. 그런 다음 지수 분포 또는 로그 정규 분포와 같은 대체 분포에 대한 거듭제곱 법칙 분포의 (로그) 우도비를 비교합니다.[20]
Zipf의 법칙은 항목 빈도 데이터를 로그-로그 그래프에 표시하여 시각화할 수 있으며, 축은 순위 순서의 로그이고 빈도의 로그입니다. 데이터는 그림이 기울기 -s를 갖는 선형(더 정확하게는 아핀) 함수와 근사하는 정도까지 지수를 갖는 Zipf의 법칙을 따릅니다. 지수 s = 1의 경우, 순위에 대한 빈도(mean 단어 간 간격)의 역수 또는 빈도에 대한 순위의 역수를 표시하고 기울기 1이 있는 원점을 통한 선과 결과를 비교할 수도 있습니다.
통계설명
비록 집프의 법칙이 에스페란토와 같이 자연어가 아닌 언어들도 대부분 포함하고 있지만, [21]그 이유는 여전히 잘 이해되지 않고 있습니다.[22] Zipf의 법칙에 대한 생성 과정에 대한 최근의 리뷰는 다음과 같습니다.[23][24]
다만 무작위로 생성된 텍스트에 대한 통계 분석으로 일부 설명될 수 있습니다. Wentian Li는 각 문자가 모든 문자(게다가 공백 문자)의 균일한 분포에서 무작위로 선택된 문서에서 길이가 다른 "단어"는 Zipf의 법칙의 거시적 추세를 따른다는 것을 보여주었습니다(가능성이 높은 단어일수록 동일한 확률로 가장 짧습니다).[25] 1959년, 비톨드 벨레비치(Vitold Bellevitch)는 잘 행동하는 통계 분포의 큰 클래스 중 하나(정규 분포뿐만 아니라)가 순위로 표현되고 테일러 급수로 확장되면 급수의 1차 절단이 집프의 법칙으로 귀결된다는 것을 관찰했습니다. 게다가 테일러 급수의 2차 절단은 만델브로의 법칙으로 이어졌습니다.[26][27]
최소 노력의 원리는 또 다른 가능한 설명입니다. Zipf 자신은 주어진 언어를 사용하는 화자나 청자가 이해에 도달하기 위해 필요 이상으로 열심히 일하고 싶어하지 않는다고 제안했으며, 거의 동일한 노력의 분배를 초래하는 프로세스는 관찰된 Zipf 분포로 이어집니다.[5][28]
최소한의 설명은 원숭이가 무작위로 타자를 쳐서 단어가 생성된다고 가정합니다. 한 마리의 원숭이가 무작위로 입력하여 각 글자 키나 흰 칸을 칠 확률이 고정되고 0이 아닌 언어가 생성되면 원숭이가 생성하는 단어(흰 칸으로 구분된 글자 문자열)는 집프의 법칙을 따릅니다.[29]
Zipf 분포의 또 다른 가능한 원인은 항목의 값 x가 x에 비례하는 비율로 증가하는 경향이 있는 우선 첨부 프로세스(직관적으로 "부자가 더 부자가 된다" 또는 "성공이 성공을 낳는다")입니다. 이러한 성장 과정은 Yule-Simon 분포를 초래하며, Zipf의 법칙보다 언어[30] 및 인구 및 도시 순위에서[31] 단어 빈도 대 순위에 더 잘 맞는 것으로 나타났습니다. 이는 원래 Yule에 의해 개체수 대 종 순위를 설명하기 위해 파생되었으며, Simon에 의해 도시에 적용되었습니다.
유사한 설명은 공정 순위에만 의존하는 드리프트 및 분산 매개변수가 있는 교환 가능한 양의 값 확산 공정 시스템인 아틀라스 모델을 기반으로 합니다. Zipf의 법칙은 특정한 자연 규칙성 조건을 만족하는 Atlas 모델에 대해 성립한다는 것을 수학적으로 보여주었습니다.[32][33] 준-집피안 분포는 준-아틀라스 모델에서 비롯될 수 있습니다.[citation needed]
관련법
집프의 법칙을 일반화한 것은 베누아 만델브로가 제안한 집프-만델브로 법칙이며, 그 빈도는 다음과 같습니다.
- [clar화 필요]

상수 C는 s에서 평가된 후르비츠 제타 함수입니다.
Zipfian 분포는 변수 교환을 통해 Pareto 분포에서 얻을 수 있습니다.[19]
Zipf 분포는 이산 균일 분포가 연속 균일 분포와 유사한 것과 같은 방식으로 연속형 파레토 분포와 유사하기 때문에 이산형 파레토[34] 분포라고 불리기도 합니다.
Yule-Simon 분포의 꼬리 주파수는 대략적으로
![{\displaystyle f(k;\rho )\approx {\frac {[{\text{constant}}]}{k^{\rho +1}}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/78fb2a5a8523f03c5e11716e40fd9627c18ff49f)
ρ > 0 중 어느 하나를 선택할 수 있습니다.
포물선 프랙탈 분포에서 빈도의 로그는 순위의 로그의 2차 다항식입니다. 이것은 단순한 멱법칙 관계보다 적합도를 현저하게 향상시킬 수 있습니다.[35] 프랙탈 차원과 마찬가지로 텍스트 분석에 유용한 파라미터인 Zipf 차원을 계산할 수 있습니다.[36]
벤포드 법칙은 통계 물리학과 임계 현상에서 비롯된 규모 불변 함수 관계에서 비롯된 이 두 법칙 사이의 연관성으로 설명되는 [35]Zipf 법칙의 특별한 경계 사례라고 주장되었습니다.[37] 벤포드 법칙의 확률 비율은 일정하지 않습니다. s = 1로 Zipf의 법칙을 만족하는 데이터의 선두 숫자는 Benford의 법칙을 만족합니다.
| 벤포드 법칙: = P(n) =} | ||
|---|---|---|
| 1 | 0.30103000 | |
| 2 | 0.17609126 | −0.7735840 |
| 3 | 0.12493874 | −0.8463832 |
| 4 | 0.09691001 | −0.8830605 |
| 5 | 0.07918125 | −0.9054412 |
| 6 | 0.06694679 | −0.9205788 |
| 7 | 0.05799195 | −0.9315169 |
| 8 | 0.05115252 | −0.9397966 |
| 9 | 0.04575749 | −0.9462848 |



발생사항
도시규모
1913년 아우어바흐의 관찰에 따라 도시 크기에 대한 집프의 법칙에 대한 실질적인 검토가 있었습니다.[38] 그러나 보다 최근의[39][40] 실증적이고[41] 이론적인 연구들은 도시에 대한 Zipf의 법칙의 관련성에 이의를 제기했습니다.
자연어의 단어 빈도수

인간 언어의 많은 텍스트에서 단어 빈도는 지수가 1에 가까운 Zipf 분포를 따릅니다. 즉, 가장 일반적인 단어는 n번째로 가장 일반적인 단어의 약 n배입니다.
자연어 텍스트의 실제 순위 빈도 그림은 특히 범위의 두 끝에서 이상적인 Zipf 분포에서 어느 정도 벗어납니다. 편차는 언어, 텍스트 주제, 저자, 텍스트가 다른 언어에서 번역되었는지 여부 및 사용된 철자 규칙에 따라 달라질 수 있습니다.[citation needed] 표본오차 때문에 어느 정도의 편차는 불가피합니다.
순위가 N에 접근하는 저주파 끝에서는 각 단어가 정수 번만 발생할 수 있기 때문에 그림이 계단 모양을 취합니다.
- 여러 언어에 대한 Zipf의 법칙도
-

-

-
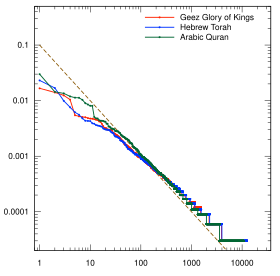
-

-

-
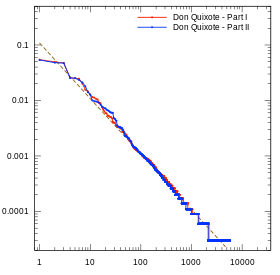 세르반테스의 돈키호테, 1부(1605)와 2부(1615).
세르반테스의 돈키호테, 1부(1605)와 2부(1615). -
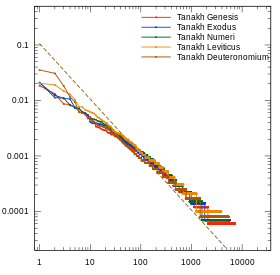
-

-


_and_Portuguese_(Dom_Casmurro).svg)








일부 로망스 언어에서는 십여 개의 가장 빈번한 단어의 빈도가 이상적인 Zipf 분포에서 크게 벗어나는데, 이러한 단어들은 문법적 성별과 수에 따라 굴절된 기사를 포함하기 때문입니다.[citation needed]
중국어, 라싸 티베트어, 베트남어와 같은 많은 동아시아 언어에서 각 "단어"는 하나의 음절로 구성되어 있습니다; 영어 단어는 종종 그러한 두 음절의 합성어로 번역됩니다. 이러한 "단어"에 대한 순위 빈도표는 범위의 양쪽 끝에 있는 이상적인 Zipflaw에서 크게 벗어납니다.[citation needed]
영어에서도 많은 양의 텍스트 모음을 조사할수록 이상적인 집프의 법칙으로부터의 편차가 더욱 분명해집니다. 30,000개의 영어 텍스트 코퍼스를 분석한 결과, 그 안에 있는 텍스트의 약 15%만이 집프의 법칙에 적합한 것으로 나타났습니다. Zipf 법칙의 정의에 약간의 변화가 있으면 이 비율이 50%[42] 가까이까지 증가할 수 있습니다.
이러한 경우 관찰된 빈도-순위 관계는 다른 하위 집합 또는 하위 유형의 단어에 대한 별도의 Zipf-Mandelbrot 법칙 분포에 의해 보다 정확하게 모델링될 수 있습니다. 이것은 영어 위키백과의 첫 1천만 단어의 빈도 순위 도표의 경우입니다. 특히, 영어에서 기능 단어의 폐쇄 클래스의 빈도는 1보다 낮게 더 잘 설명되는 반면, 문서 크기와 말뭉치 크기를 가진 개방형 어휘 증가는 Generalized Harmonic Series의 수렴을 위해 1보다 큰 것이 필요합니다.[3]

각각의 고유한 평문 단어의 모든 발생이 항상 동일한 암호화된 단어에 매핑되도록 텍스트가 암호화되는 경우(예를 들어 시저 암호나 단순 코드북 암호의 경우와 같이), 빈도 순위 분포는 영향을 받지 않습니다. 반면, 동일한 단어의 개별적인 발생이 두 개 이상의 다른 단어에 매핑될 수 있는 경우(Vigenère 암호에서 발생하는 것처럼), Zipf 분포는 일반적으로 고주파수 끝에 평평한 부분을 갖게 됩니다.[citation needed]
적용들
Zipf의 법칙은 유사한 corpora에서 병렬 텍스트 조각을 추출하는 데 사용되었습니다.[43] Laurance Doyle과 다른 사람들은 외계 지능을 찾는 데 있어 외계어를 탐지하기 위해 Zipf의 법칙을 적용할 것을 제안했습니다.[44][45]
빈도 순위 단어 분포는 종종 저자의 특징이며 시간이 지남에 따라 거의 변하지 않습니다. 이 기능은 저자 귀속 텍스트 분석에 사용되었습니다.[46][47]
15세기 코덱스 보이니치 원고의 단어와 같은 기호 그룹은 집프의 법칙을 만족하는 것으로 밝혀졌으며, 이는 텍스트가 거짓말이 아니라 모호한 언어나 암호로 작성되었을 가능성이 높다는 것을 암시합니다.[48][49]
참고 항목
- 1% 규칙(인터넷 문화) – 커뮤니티에 더 많은 사람이 숨어있을 것이라는 가설 리디렉션 되는 페이지
- Benford의 법칙 – 많은 실제 데이터 세트에서 선두 자리가 작을 가능성이 높다는 관측
- Bradford의 법칙 – 과학 저널의 참조 패턴
- 간결성 법칙 – 언어학 법칙
- 인구학적 인력
- 빈도 목록 – 말뭉치 언어학에서 언어 단어의 맨 위 목록 대상에 을 표시하는 페이지
- 기브라트의 법칙 – 경제 원리
- Hapax legomenon – 주어진 텍스트 또는 레코드에서 한 번만 나타나는 단어
- Heaps' law – 문서에서 구별되는 단어에 대한 휴리스틱
- King effect – 가장 높은 순위의 데이터 점이 특이치인 통계량에서 나타나는 현상
- 긴 꼬리 – 일부 통계 분포의 특징
- 로렌츠 곡선 – 소득 또는 부의 분포를 그래프로 표시
- Lotka's law – 주어진 분야에서 저자의 출판 빈도를 기술하는 Zipf's law의 적용
- 멘제라스의 법칙 – 언어 법칙
- 파레토 분포 – 확률 분포
- 파레토 원리 – 원인에 대한 효과 비율에 대한 통계적 원리, 예를 들어 "80–20 규칙"
- 가격의 법칙 – 하는 과학 페이지의 역사가
- 최소 노력의 원칙 – 에이전트가 가장 쉬운 작업을 선호하는 아이디어
- 순위 크기 분포 – 순위별 크기 분포
- 스티글러의 시문 법칙 – 어떠한 과학적 발견도 발견자의 이름을 따서 명명되지 않는 것을 관찰
- 문자빈도
- 영어에서 가장 흔한 단어는
메모들
참고문헌
- ^ a b c Piantadosi, Steven (March 25, 2014). "Zipf's word frequency law in natural language: A critical review and future directions". Psychon Bull Rev. 21 (5): 1112–1130. doi:10.3758/s13423-014-0585-6. PMC 4176592. PMID 24664880.
- ^ Fagan, Stephen; Gençay, Ramazan (2010), "An introduction to textual econometrics", in Ullah, Aman; Giles, David E. A. (eds.), Handbook of Empirical Economics and Finance, CRC Press, pp. 133–153, ISBN 9781420070361Fagan, Stephen; Gençay, Ramazan (2010), "An introduction to textual econometrics", in Ullah, Aman; Giles, David E. A. (eds.), Handbook of Empirical Economics and Finance, CRC Press, pp. 133–153, ISBN 9781420070361139쪽: "예를 들어, 백만 개 이상의 단어로 구성된 갈색 말뭉치에서, 단어 부피의 절반은 단지 135개의 단어만을 반복적으로 사용하는 것으로 구성되어 있습니다."
- ^ a b c Powers, David M W (1998). Applications and explanations of Zipf's law. Joint conference on new methods in language processing and computational natural language learning. Association for Computational Linguistics. pp. 151–160. Archived from the original on 2015-09-10. Retrieved 2015-02-02.
- ^ a b 조지 K. 집프 (1935): 언어의 심리생물학. Houghton-Mifflin.
- ^ a b c George K. Zipf (1949). Human Behavior and the Principle of Least Effort. Cambridge, Massachusetts: Addison-Wesley. p. 1.
- ^ Auerbach F. (1913) Das Gesetz der Bevölkerungskonzentration. 피터만의 지리학 미테일룽겐 59, 74–76
- ^ 크리스토퍼 D. Manning, Hinrich Schüze Foundations of Statistical Natural Language Processing, MIT Press (1999), ISBN 978-0-262-13360-9, 페이지 24
- ^ 듀이, 갓프리. 영어 스피치 사운드의 상대적 빈도. 하버드 대학교 출판부, 1923
- ^ 콘돈, 에드워드 U "어휘 통계" 과학 67.1733 (1928): 300-300.
- ^ 조지 K. 집프 (1932): 언어의 상대적 빈도 원리에 대한 선별된 연구. 하버드, MA: 하버드 대학 출판부.
- ^ Zipf, George Kingsley (1942). "The Unity of Nature, Least-Action, and Natural Social Science". Sociometry. 5 (1): 48–62. doi:10.2307/2784953. ISSN 0038-0431. JSTOR 2784953. Archived from the original on 2022-11-20. Retrieved 2022-11-20.
- ^ Axtell, Robert L(2001): 미국 기업 규모의 Zipf 배포 2023-10-17 Wayback Machine, Science, 293, 5536, 1818, American Association for the Advancement of Science.
- ^ Sandmo, Agnar (2015-01-01), Atkinson, Anthony B.; Bourguignon, François (eds.), Chapter 1 - The Principal Problem in Political Economy: Income Distribution in the History of Economic Thought, Handbook of Income Distribution, vol. 2, Elsevier, pp. 3–65, doi:10.1016/B978-0-444-59428-0.00002-3, archived from the original on 2023-10-29, retrieved 2023-07-11
- ^ M. 에릭손, S.M. 하시부르 라만, F. Fraille, M. Schöström, 효율적인 대화형 멀티캐스트 over DVB-T2 - Wayback Machine에서 Dynamic SFN 및 PARPS Archive 2014-05-02 활용, 2013 IEEE 국제 컴퓨터 및 정보 기술 회의(BMSB'13), 영국 런던, 2013년 6월. 이질적인 Zipflaw TV 채널 선택 모델 제안
- ^ Zanette, Damián H. (June 7, 2004). "Zipf's law and the creation of musical context". arXiv:cs/0406015.
- ^ Lazzardi, Silvia; Valle, Filippo; Mazzolini, Andrea; Scialdone, Antonio; Caselle, Michele; Osella, Matteo (2021-06-17). "Emergent Statistical Laws in Single-Cell Transcriptomic Data". bioRxiv: 2021–06.16.448706. doi:10.1101/2021.06.16.448706. S2CID 235482777. Archived from the original on 2021-06-17. Retrieved 2021-06-18.
- ^ Ramu Chenna, Toby Gibson; Wayback Machine, International Conference on Bioinformatics Computational Biology: 2011에서 보관된 쌍별 서열 정렬을 위한 Zipfian Gap 모델의 적합성 평가.
- ^ Li, Wentian (1992). "Random texts exhibit Zipf's-law-like word frequency distribution". EEE Transactions on Information Theory. 38 (6): 1842–1845 – via IEEE Xplore.
- ^ a b Adamic, Lada A. (2000). Zipf, power-laws, and Pareto - a ranking tutorial (Report). Hewlett-Packard Company. Archived from the original on 2023-04-01. Retrieved 2023-10-12. "originally published". www.parc.xerox.com. Xerox Corporation. Archived from the original on 2001-11-07. Retrieved 2016-02-23.
- ^ Clauset, A., Shalizi, C.R., & Newman, M.E.J. (2009) 경험적 데이터의 Power-Law 분포. SIAM Review, 51(4), 661–703. doi:10.1137/070710111
- ^ Bill Manaris; Luca Pellicoro; George Pothering; Harland Hodges (13 February 2006). Investigating Esperanto's statistical proportions relative to other languages using neural networks and Zipf's law (PDF). Artificial Intelligence and Applications. Innsbruck, Austria. pp. 102–108. Archived from the original (PDF) on 5 March 2016.
- ^ Léon Brillouin, La science et la Théorie de l' information, 1959, réditéen 1988, traduction anglaise réditéen 2004
- ^ Mitzenmacher, Michael (January 2004). "A Brief History of Generative Models for Power Law and Lognormal Distributions". Internet Mathematics. 1 (2): 226–251. doi:10.1080/15427951.2004.10129088. ISSN 1542-7951. S2CID 1671059. Archived from the original on 2023-07-22. Retrieved 2023-07-25.
- ^ Simkin, M. V.; Roychowdhury, V. P. (2011-05-01). "Re-inventing Willis". Physics Reports. 502 (1): 1–35. arXiv:physics/0601192. Bibcode:2011PhR...502....1S. doi:10.1016/j.physrep.2010.12.004. ISSN 0370-1573. S2CID 88517297. Archived from the original on 2012-01-29. Retrieved 2023-07-25.
- ^ Wentian Li (1992). "Random Texts Exhibit Zipf's-Law-Like Word Frequency Distribution". IEEE Transactions on Information Theory. 38 (6): 1842–1845. CiteSeerX 10.1.1.164.8422. doi:10.1109/18.165464.
- ^ Belevitch V (18 December 1959). "On the statistical laws of linguistic distributions" (PDF). Annales de la Société Scientifique de Bruxelles. 73: 310–326. Archived (PDF) from the original on 15 December 2020. Retrieved 24 April 2020.
- ^ Neumann, Peter G. "통계 금속언어학과 Zipf/Pareto/Mandelbrot", SRI 국제 컴퓨터 과학 연구소, 2011년 5월 29일 접속 및 보관.
- ^ Ramon Ferrer i Cancho & Ricard V. Sole (2003). "Least effort and the origins of scaling in human language". Proceedings of the National Academy of Sciences of the United States of America. 100 (3): 788–791. Bibcode:2003PNAS..100..788C. doi:10.1073/pnas.0335980100. PMC 298679. PMID 12540826.
- ^ Conrad, B.; Mitzenmacher, M. (July 2004). "Power laws for monkeys typing randomly: the case of unequal probabilities". IEEE Transactions on Information Theory. 50 (7): 1403–1414. doi:10.1109/TIT.2004.830752. ISSN 1557-9654. S2CID 8913575. Archived from the original on 2022-10-17. Retrieved 2023-08-20.
- ^ Lin, Ruokuang; Ma, Qianli D. Y.; Bian, Chunhua (2014). "Scaling laws in human speech, decreasing emergence of new words and a generalized model". arXiv:1412.4846 [cs.CL].
- ^ Vitanov, Nikolay K.; Ausloos, Marcel; Bian, Chunhua (2015). "Test of two hypotheses explaining the size of populations in a system of cities". Journal of Applied Statistics. 42 (12): 2686–2693. arXiv:1506.08535. Bibcode:2015JApSt..42.2686V. doi:10.1080/02664763.2015.1047744. S2CID 10599428.
- ^ Ricardo T. Fernholz; Robert Fernholz (December 2020). "Zipf's law for atlas models". Journal of Applied Probability. 57 (4): 1276–1297. doi:10.1017/jpr.2020.64. S2CID 146808080. Archived from the original on 2021-01-29. Retrieved 2021-03-26.
- ^ Terence Tao (2012). "E Pluribus Unum: From Complexity, Universality". Daedalus. 141 (3): 23–34. doi:10.1162/DAED_a_00158. S2CID 14535989. Archived from the original on 2021-08-05. Retrieved 2021-03-26.
- ^ N. L. Johnson; S. Kotz & A. W. Kemp (1992). Univariate Discrete Distributions (second ed.). New York: John Wiley & Sons, Inc. ISBN 978-0-471-54897-3.N. L. Johnson; S. Kotz & A. W. Kemp (1992). Univariate Discrete Distributions (second ed.). New York: John Wiley & Sons, Inc. ISBN 978-0-471-54897-3.p. 466
- ^ a b Johan Gerard van der Galien (2003-11-08). "Factorial randomness: the Laws of Benford and Zipf with respect to the first digit distribution of the factor sequence from the natural numbers". Archived from the original on 2007-03-05. Retrieved 8 July 2016.
- ^ Eftekhari, Ali (2006). "Fractal geometry of texts: An initial application to the works of Shakespeare". Journal of Quantitative Linguistic. 13 (2–3): 177–193. doi:10.1080/09296170600850106. S2CID 17657731.
- ^ Pietronero, L.; Tosatti, E.; Tosatti, V.; Vespignani, A. (2001). "Explaining the uneven distribution of numbers in nature: The laws of Benford and Zipf". Physica A. 293 (1–2): 297–304. Bibcode:2001PhyA..293..297P. doi:10.1016/S0378-4371(00)00633-6.
- ^ Gabaix, Xavier (1999). "Zipf's Law for Cities: An Explanation". The Quarterly Journal of Economics. 114 (3): 739–767. doi:10.1162/003355399556133. ISSN 0033-5533. JSTOR 2586883. Archived from the original on 2021-10-26. Retrieved 2021-10-26.
- ^ Arshad, Sidra; Hu, Shougeng; Ashraf, Badar Nadeem (2018-02-15). "Zipf's law and city size distribution: A survey of the literature and future research agenda". Physica A: Statistical Mechanics and Its Applications. 492: 75–92. Bibcode:2018PhyA..492...75A. doi:10.1016/j.physa.2017.10.005. ISSN 0378-4371. Archived from the original on 2023-10-29. Retrieved 2021-10-26.
- ^ Gan, Li; Li, Dong; Song, Shunfeng (2006-08-01). "Is the Zipf law spurious in explaining city-size distributions?". Economics Letters. 92 (2): 256–262. doi:10.1016/j.econlet.2006.03.004. ISSN 0165-1765. Archived from the original on 2019-04-13. Retrieved 2021-10-26.
- ^ Verbavatz, Vincent; Barthelemy, Marc (November 2020). "The growth equation of cities". Nature. 587 (7834): 397–401. arXiv:2011.09403. Bibcode:2020Natur.587..397V. doi:10.1038/s41586-020-2900-x. ISSN 1476-4687. PMID 33208958. S2CID 227012701. Archived from the original on 2021-10-29. Retrieved 2021-10-26.
- ^ Moreno-Sánchez, I.; Font-Clos, F.; Corral, A. (2016). "Large-scale analysis of Zipf's Law in English texts". PLOS ONE. 11 (1): e0147073. arXiv:1509.04486. Bibcode:2016PLoSO..1147073M. doi:10.1371/journal.pone.0147073. PMC 4723055. PMID 26800025.
- ^ Mohammadi, Mehdi (2016). "Parallel Document Identification using Zipf's Law" (PDF). Proceedings of the Ninth Workshop on Building and Using Comparable Corpora. LREC 2016. Portorož, Slovenia. pp. 21–25. Archived (PDF) from the original on 2018-03-23.
- ^ Doyle, Laurance R. (2016-11-18). "Why Alien Language Would Stand Out Among All the Noise of the Universe". Nautilus Quarterly. Archived from the original on 2020-07-29. Retrieved 2020-08-30.
- ^ Kershenbaum, Arik (2021-03-16). The Zoologist's Guide to the Galaxy: What Animals on Earth Reveal About Aliens--and Ourselves. Penguin. pp. 251–256. ISBN 978-1-9848-8197-7. OCLC 1242873084.
- ^ Fans J. Van Droogenbroeck (2016): 전산화된 작성자 속성으로 Zipf 배포 처리 Wayback Machine에서 아카이브된 2023-10-04
- ^ Fans J. Van Droogenbroeck (2019): 가우스 통계에 의한 저작자 귀속 신청을 해결하기 위한 Zipf-Mandelbrot 법의 필수적인 표현 방법 Wayback Machine에서 아카이브된 2023-09-30
- ^ Boyle, Rebecca. "Mystery text's language-like patterns may be an elaborate hoax". New Scientist. Archived from the original on 2022-05-18. Retrieved 2022-02-25.
- ^ Montemurro, Marcelo A.; Zanette, Damián H. (2013-06-21). "Keywords and Co-Occurrence Patterns in the Voynich Manuscript: An Information-Theoretic Analysis". PLOS ONE. 8 (6): e66344. Bibcode:2013PLoSO...866344M. doi:10.1371/journal.pone.0066344. ISSN 1932-6203. PMC 3689824. PMID 23805215.
더보기
- Alexander Gelbukh and Grigori Sidorov (2001) "Zipf and Heaps Laws' 계수는 언어에 의존합니다." 프록. CICLing-2001, 지능형 텍스트 처리 및 컴퓨터 언어학 회의, 2001년 2월 18일-24일, 멕시코시티. 컴퓨터 과학 N 2004, ISSN 0302-9743, ISBN 3-540-41687-0, Springer-Verlag: 332–335.
- Kali R. (2003) "거대한 구성요소로서의 도시: Zipf의 법칙에 대한 임의의 그래프 접근", 응용경제학 편지 10: 717–720(4)
- Shyklo A. (2017); 순위 프로세스의 조합론에서 도출된 새로운 순위-점유율 분포를 통한 Zipf의 미스터리에 대한 간단한 설명은 SSRN: https://ssrn.com/abstract=2918642 에서 확인할 수 있습니다.
외부 링크
| 라이브러리 리소스 정보 집프의 법칙 |
- Strogatz, Steven (2009-05-29). "Guest Column: Math and the City". The New York Times. Archived from the original on 2015-09-27. Retrieved 2009-05-29.—도시인구에 적용되는 Zipf의 법칙에 관한 기사
- 구석구석 보기(인공 사회에서 Zipf의 법칙이 나타남)
- 집프의 법칙에 관한 행성수학 기사
- 배포 유형 "fractal parabolique" dansla Nature (프랑스어, 영문 요약 포함) Wayback Machine에서 아카이브된 2004-10-24
- 소득분포 분석
- Wayback Machine에서 보관된 프랑스어 단어 Zipf 목록 2007-06-23
- Gutenberg Project의 영어, 프랑스어, 스페인어, 이탈리아어, 스웨덴어, 아이슬란드어, 라틴어, 포르투갈어 및 핀란드어에 대한 Zipf 목록과 Wayback Machine에서 보관된 텍스트의 단어 순위를 매기는 온라인 계산기 2011-04-08
- 인용과 집프-만델브로의 법칙
- Zipf's Law 사례와 모델링 (1985)
- 복잡한 시스템: Zipf's law (2011)
- 벤포드 법칙, 집프 법칙, 테렌스 타오의 파레토 분포.
- "Zipf law", Encyclopedia of Mathematics, EMS Press, 2001 [1994]
| 이산형 일변의 |
| ||||||||
|---|---|---|---|---|---|---|---|---|---|
| 계속되는 일변의 |
| ||||||||
| 혼합 일변의 |
| ||||||||
| 다변량 (공동) | |||||||||
| 방향성 | |||||||||
| 퇴화 그리고 단수의 | |||||||||
| 가족들 | |||||||||

