p값
p-value귀무-히포테시스 유의성 검정에서 p-값은[note 1] 귀무 가설이 [2][3]올바르다고 가정할 때 최소한 실제로 관측된 결과와 같은 극단적인 검정 결과를 얻을 확률입니다.p-값이 매우 작다는 것은 귀무 가설에서 극단적으로 관측된 결과가 발생할 가능성이 매우 낮다는 것을 의미합니다.통계적 검정의 p-값 보고는 많은 정량적 분야의 학술 간행물에서 흔히 볼 수 있는 관행이다.p-값의 정확한 의미는 파악하기 어렵기 때문에 오남용이 만연하고 메타과학의 [4][5]주요 주제이다.
기본 개념
통계학에서 일부 연구에서 관측된 X X를 나타내는 랜덤 변수 집합의 알 수 없는 확률 분포에 관한 모든 추측을 통계 가설이라고 한다.하나의 가설만 진술하고 통계 검정의 목적은 이 가설이 성립할 수 있는지 여부를 확인하는 것이며 다른 특정 가설을 조사하는 것이 아니라면 이러한 검정을 귀무 가설 검정이라고 합니다.
 나타내는 랜덤 변수 집합의 알 수 없는 확률 분포에 관한 모든 추측을 통계 가설이라고 한다.하나의 가설만 진술하고 통계 검정의 목적은 이 가설이 성립할 수 있는지 여부를 확인하는 것이며 다른 특정 가설을 조사하는 것이 아니라면 이러한 검정을
나타내는 랜덤 변수 집합의 알 수 없는 확률 분포에 관한 모든 추측을 통계 가설이라고 한다.하나의 가설만 진술하고 통계 검정의 목적은 이 가설이 성립할 수 있는지 여부를 확인하는 것이며 다른 특정 가설을 조사하는 것이 아니라면 이러한 검정을 우리의 통계 가설이, 정의상, 분포의 몇 가지 속성을 기술할 것이기 때문에, 귀무 가설은 그 속성이 존재하지 않는 기본 가설이다.귀무 가설은 일반적으로 관심 모집단의 일부 모수(예: 상관 관계 또는 평균 간의 차이)가 0이라는 것입니다.이 가설에서는의 분포를 정확하게 지정하거나 특정 분포 클래스에 속한다는 것만 지정할 수 있습니다.종종 데이터를 단일 수치 통계량(예: T{\T으로 축소하며, 한계 확률 분포는 연구의 주요 관심사와 밀접하게 관련되어 있다.

p-값은 결과의 유의성을 정량화하기 위해 귀무 가설 테스트의 맥락에서 사용된다이 작을수록 귀무 가설이 참일 경우 결과를 얻을 확률은 낮아진다[note 2]귀무 가설을 기각할 수 있다면 결과는 통계적으로 유의하다고 한다.다른 모든 사항이 동일할 경우 p-값이 작을수록 귀무 가설에 대한 강력한 증거로 간주됩니다.
대략적으로 말하면, 귀무 가설에 대한 거절은 그것에 대한 충분한 증거가 있다는 것을 의미한다.
예를 들어, 귀무 가설에서 특정 요약 Tdisplaystyle T)가 표준 정규 분포 N(0,1)을 따른다고 하는 경우, 이 귀무 가설의 기각은 (i)T({T})의 평균이 0이 아님 또는 (ii T({ T의 분산이 1이 아님을 의미할 수 있다.T는 정규 분포를 따르지 않습니다.동일한 귀무 가설에 대한 다른 검정은 다른 대안에 대해 다소 민감합니다.그러나 세 가지 대안 모두에 대해 귀무 가설을 기각하고 분포가 정규 분포이고 분산이 1이라고 하더라도 귀무 가설 검정을 통해 평균의 0이 아닌 값이 현재 가장 타당한지 알 수 없습니다.동일한 확률 분포에서 더 독립적인 관측치를 가질수록 검정은 더 정확해지고 평균값을 결정할 수 있는 정밀도가 높아지며 0과 같지 않다는 것을 보여준다. 그러나 이것은 또한 이 dev의 실제 세계 또는 과학적 관련성을 평가하는 중요성을 증가시킬 것이다.intion.
정의와 해석
정의.
실제 값 검정 통계량을 얻을 확률(최소한 실제 검정 통계량)
미지의 TT에서 관측된 검정 통계({ t를 고려합니다. 그러면 p({p})는 귀무 가설 w인 경우(최소값) "극한" 검정 통계 값을 관측할 확률이 됩니다.진짜가 아니다.즉, 다음과 같습니다.

 고려합니다. 그러면
고려합니다. 그러면 
- ( T tH 0) { p = \ ( \ t \ H _ { } } (일측 우측 꼬리 테스트의 경우)
- ( t H 0) { p = \( T \ \ H _ {0 } } (단측 좌측 꼬리 테스트의 경우)
- { ( H ) , ( t H0 ) , Pr \ p \\ { \ \ \ H _ { } ) , \ ( \ t \ mid H _ 0) 。 T의 분포가 0에 대해 대칭인 경우 ( T t ) { \ p = \ \ t \ H _ { } )



 분포가 0에 대해 대칭인 경우
분포가 0에 대해 대칭인 경우 해석
유의성 검정을 수행하기 위한 통계량으로서의 p-값
유의성 테스트에서 p-값이 사전 정의된 알파 수준 또는 유의 수준 이하인 경우 H displaystyle 이 거부됩니다.α는 데이터에서 도출된 것이 아니라 연구자가 데이터를 검토하기 전에 설정한다.α는 일반적으로 0.05로 설정되지만 낮은 알파 레벨이 사용되는 경우도 있습니다.

p-값은 선택한 검정 T T의 함수이므로 랜덤 변수입니다. 가설이 분포를 정확하게 고정하고 해당 분포가 연속적인 경우 귀무-하이포테시스가 참일 경우 p-값은 0과 1 사이에서 균일하게 분포됩니다.따라서 p-값은 고정되지 않습니다.동일한 검정이 새로운 데이터로 독립적으로 반복되면 일반적으로 각 반복에서 다른 p-값을 얻을 수 있습니다.null-hypothesis가 합성되거나 통계량의 분포가 이산형인 경우 0과 1 사이의 숫자보다 작거나 같은 p-값을 얻을 확률은 null-hypothesis가 참이면 이 숫자보다 작거나 같습니다.null-hypothesis가 참일 경우 매우 작은 값은 비교적 드물며, 유의 이α 일 경우 null-hypothesis를 거부하여 수준α(\에서의 유의성 테스트를 얻을 수 있다.
예를 들어, Fisher의 결합된 확률 검정을 사용하여 독립적인 데이터 집합을 기반으로 하는 다른 p-값을 결합할 수 있습니다.
분배
귀무 가설이 참일 경우, 0 : = {\ =\ _ 이고 기본 랜덤 변수가 연속형이면 p-값의 확률 분포는 [0,1] 구간에서 균일합니다.반면 대립 가설이 참인 경우 분포는 표본 크기와 [6][7]연구 중인 모수의 참 값에 따라 달라집니다.

연구 그룹에 대한 p-값의 분포를 [8]p-곡선이라고도 합니다.p-곡선은 출판 편향 또는 p-해킹 [8][9]검출과 같은 과학 문헌의 신뢰성을 평가하기 위해 사용될 수 있다.
합성 가설의 경우
모수 가설 검정 문제에서 단순 또는 점 가설은 모수의 값이 단일 숫자로 가정되는 가설을 가리킵니다.반면, 합성 가설에서는 모수 값이 숫자 집합으로 제공됩니다.예를 들어, 평균이 0보다 크다는 대안에 대해 평균이 0보다 작거나 같다는 귀무 가설을 검정하는 경우 귀무 가설은 적절한 검정 통계량의 확률 분포를 지정하지 않습니다.방금 언급한 예제에서는 단측 단표본 Z 검정에 속하는 Z 통계량입니다.이론 평균의 가능한 각 값에 대해 Z 검정 통계량의 확률 분포는 서로 다릅니다.이러한 상황(일명 복합 귀무 가설의 경우)에서 p-값은 일반적으로 귀무와 대안 사이의 경계에 있는 가장 바람직하지 않은 귀무-최적화 경우를 취함으로써 정의된다.
이 정의는 p-값과 알파 수준의 상호보완성을 보장합니다.유의 수준 알파를 0.05로 설정하고 p-값이 0.05보다 작거나 같은 경우에만 귀무 가설을 기각하면 가설 검정의 유의 수준(최대 유형 1 오류율) 0.05가 됩니다.네이먼이 썼듯이: "실천하는 통계학자가 피하는 것이 더 중요하다고 생각하는 오류를 제1종 오류라고 한다.수학 이론의 첫 번째 요구는 첫 번째 종류의 오류를 범할 확률이 α = 0.05 또는 0.01 등과 같이 사전 할당된 숫자 α와 같거나(또는 거의 같거나 초과하지 않도록) 보장하는 테스트 기준을 추론하는 것이다.이 숫자를 유의 수준이라고 합니다."Neyman 1976, "수학 통계학의 출현: 미국을 특별히 참조한 역사적 스케치", "통계학과 확률의 역사에 대하여", Ed. D.B. Owen, New York: Marcel Dekker, 페이지 149-193.미국 통계학자 레이먼드 허버드와 M. J. 바야리, 2003년 8월, 제57권, No 3, 171-182(논의)를 참조한다.현대적인 간결한 진술에 대해서는 "통계: 통계추론의 간결한 과정"의 10장, 스프링거; 제1차 수정판 20호(2004년 9월 17일)를 참조한다.래리 워서맨.
사용.
p-값은 통계 가설 검정, 특히 귀무 가설 유의성 검정에 널리 사용됩니다.이 방법에서는 연구를 수행하기 전에 먼저 모형(귀무 가설)과 알파 수준 α(가장 일반적으로 0.05)를 선택합니다.데이터를 분석한 후 p-값이 α보다 작으면 관측된 데이터가 귀무 가설과 충분히 일치하지 않아 귀무 가설이 기각된다는 것을 의미합니다.그러나 그것이 귀무 가설이 거짓이라는 것을 증명하지는 않는다.p-값은 그 자체로 가설의 확률을 설정하지는 않습니다.오히려 귀무 [10]가설을 기각할지 여부를 결정하는 도구입니다.
오용
ASA에 따르면 p-값이 종종 오용되고 잘못 [3]해석된다는 데 널리 동의하고 있습니다.특히 비판을 받은 한 가지 방법은 명목상 0.05보다 작은 p-값에 대한 대립 가설을 다른 근거 없이 받아들이는 것입니다.p-값은 데이터가 특정 통계 모델과 얼마나 양립할 수 없는지를 평가하는 데 도움이 되지만, "연구의 설계, 측정의 품질, 연구 중인 현상에 대한 외부 증거,[3] 데이터 분석의 기초가 되는 가정의 타당성"과 같은 맥락적 요인도 고려해야 한다.또 다른 우려 사항은 p-값이 종종 귀무 가설이 [3][11]참일 확률로 오해된다는 것입니다.
일부 통계학자들은 p-값을 포기하고 신뢰 구간,[12][13] 우도비 [14][15]또는 베이즈 [16][17][18]요인 등 다른 추리 [3]통계량에 더 초점을 맞출 것을 제안했지만, 이러한 [19][20]대안의 실현 가능성에 대한 논쟁이 뜨겁다.다른 이들은 고정된 유의성 임계값을 제거하고 p-값을 귀무 [21][22]가설에 대한 근거 강도의 연속적 지수로 해석할 것을 제안했다.그러나 다른 이들은 p-값과 함께 사전 지정된 임계값(예: 5%)[23]보다 낮은 허위 양성 위험(즉, 실제 영향이 없을 확률)을 얻기 위해 필요한 실제 영향의 사전 확률을 보고할 것을 제안했다.
계산
으로 T디스플레이 스타일 T)는 테스트 통계량입니다.검정 통계량은 모든 관측치의 스칼라 함수의 출력입니다.이 통계량은 t-통계량 또는 F-통계량과 같은 단일 숫자를 제공합니다.따라서 검정 통계량은 해당 검정 통계량을 정의하는 데 사용되는 함수와 입력 관측 데이터의 분포를 따릅니다.
데이터가 정규 분포에서 랜덤 표본으로 가정되는 중요한 경우 검정 통계량의 특성과 분포에 대한 관심 가설에 따라 서로 다른 귀무 가설 검정이 개발되었습니다.이러한 검정은 분산이 알려진 정규 분포의 평균에 관한 가설에 대한 z 검정, 분산이 알려지지 않은 경우 정규 분포의 평균에 관한 가설에 대한 학생의 적절한 통계량에 대한 t-분포에 기초한 t 검정, 가설에 대한 F-분포에 대한 또 다른 통계량에 대한 F-검정입니다.차이에 대해서요.예를 들어 범주형(이산형) 데이터의 경우 피어슨의 카이 제곱 검정의 경우와 같이 큰 표본에 대한 중심 한계 정리를 호출하여 얻은 적절한 통계량에 대한 정규 근사에 귀무 가설 분포가 기초하는 검정 통계량을 구성할 수 있습니다.
따라서 p-값을 계산하려면 귀무 가설, 검정 통계량(연구자가 한쪽 꼬리 검정을 수행하는지 또는 양쪽 꼬리 검정을 수행하는지 여부 결정) 및 데이터가 필요합니다.주어진 데이터에 대한 검정 통계량을 계산하는 것은 쉬울 수 있지만 귀무 가설에서 표본 분포를 계산한 다음 누적 분포 함수(CDF)를 계산하는 것은 종종 어려운 문제입니다.오늘날 이 계산은 종종 (정확한 공식 대신) 숫자 방법을 통해 통계 소프트웨어를 사용하여 수행되지만, 20세기 초중반에는 대신 값 표와 이러한 이산[citation needed] 값에서 하나의 보간 또는 추정 p-값을 통해 수행되었다.p-값 표를 사용하는 대신 Fisher는 CDF를 반전하여 주어진 고정 p-값에 대한 검정 통계량 값 목록을 공개했습니다. 이는 정량함수(역 CDF)를 계산하는 것과 일치합니다.
예
코인의 공정성 테스트
통계적 테스트의 예로서 코인 플립이 공정한지(앞면 또는 뒷면의 동등한 확률) 또는 부당하게 편향된지(한 결과가 다른 결과보다 가능성이 더 높은지)를 결정하기 위해 실험을 수행한다.
실험 결과 동전이 총 20번의 공중제비 중 14번 앞면이 나온다고 가정합니다.전체 X(\ X는 기호 "H" 또는 "T"의 20배 시퀀스가 됩니다.초점을 맞출 수 있는 통계는 총 헤드 T 스타일 T가 될 수 있습니다.귀무 가설은 동전이 공정하고 동전 던지기는 서로 독립적이라는 것이다.오른쪽 꼬리 테스트를 고려할 때, 즉 코인이 떨어지는 헤드에 편향될 가능성에 실제로 관심이 있는 경우, 이 결과의 p-값은 20번의 공중제비 중 14번 이상 헤드에 공정한 코인이 착지할 확률이다.이 확률은 이항 계수에서 다음과 같이 계산할 수 있습니다.
![{\displaystyle {\begin{aligned}&\Pr(14{\text{ heads}})+\Pr(15{\text{ heads}})+\cdots +\Pr(20{\text{ heads}})\\&={\frac {1}{2^{20}}}\left[{\binom {20}{14}}+{\binom {20}{15}}+\cdots +{\binom {20}{20}}\right]={\frac {60,\!460}{1,\!048,\!576}}\approx 0.058\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/f2c59548d359fb637177e73515aea16368929436)
이 확률은 앞면에 유리한 극단적 결과만 고려할 때 p-값입니다.이것은 한 쪽 꼬리 테스트라고 불립니다.그러나 앞면이나 뒷면 중 하나를 선호하여 어느 방향의 편차에 관심이 있을 수 있습니다.대신 앞면 또는 뒷면을 선호하는 편차를 고려하는 두 개의 꼬리 p-값을 계산할 수 있습니다.이항 분포는 공정한 동전에 대해 대칭이므로 양측 p-값은 위에서 계산한 단측 p-값의 두 배입니다. 즉, 양측 p-값은 0.115입니다.
위의 예에서는 다음과 같습니다.
- 귀무 가설(H0):동전은 Pr(앞면) = 0.5로 공정합니다.
- 검정 통계:헤드 수
- 알파 수준(지정된 유의 임계값): 0.05
- 관찰 O: 20회 공중제비 중 14회, 그리고
- 주어진0 H = 2 × min(머리 수 no 14 머리 수), Pr(머리 수 heads 14 머리 수) = 2 × min(0.058, 0.978) = 2*0.058 = 0.115.
Pr(머리수 heads 14머리수) = 1 - Pr(머리수 14 14머리수) + Pr(머리수 = 14) = 1 - 0.058 + 0.036 = 0.978이라는 점에 유의한다. 그러나 이 이항분포의 대칭성으로 인해 두 확률 중 더 작은 값을 구하는 것은 불필요하다.여기서 계산된 p-값은 0.05를 초과합니다. 즉, 데이터가 실제로 동전이 공정할 경우 95%의 발생 범위에 속한다는 것을 의미합니다.따라서 귀무 가설은 0.05 수준에서 기각되지 않습니다.
그러나 머리 하나가 더 얻어진 경우 결과 p-값(양쪽 꼬리)은 0.0414(4.14%)가 되며, 이 경우 귀무 가설은 0.05 수준에서 기각됩니다.
다단계 실험 설계
동전의 공정성을 테스트하기 위한 다단계 실험을 고려할 때 "극한"의 두 가지 의미 사이의 차이는 나타난다.실험을 다음과 같이 설계한다고 가정합니다.
- 동전을 두 번 던지다.양쪽 모두 앞면 또는 뒷면이 나오면 실험을 종료합니다.
- 아니면 동전을 4번 더 던지세요.
이 실험에는 머리 2개, 꼬리 2개, 꼬리 5개, 꼬리 1개..., 꼬리 1개 등 7가지 유형의 결과가 있습니다.이제 "3개 머리 3개 꼬리" 결과의 p-값을 계산합니다.
검정 를 하는 경우(\ {heads}{tails 귀무 가설에서는 양면 p-값의 경우 정확히 1이고, 왼쪽 꼬리 p-값의 경우 이며, 오른쪽 꼬리 p-값의 경우 동일하다.

 , 오른쪽 꼬리 p-값의 경우 동일하다.
, 오른쪽 꼬리 p-값의 경우 동일하다. "3개의 머리 3개 꼬리"보다 같거나 낮은 확률을 가진 모든 결과를 "최소한 극단적"으로 간주하면 p-값은 2입니다.

그러나 어떤 일이 일어나더라도 동전을 6번 던지기로 계획했다고 가정하면 p-값의 두 번째 정의는 "3개의 앞면 3개의 꼬리"의 p-값이 정확히 1임을 의미합니다.
따라서 p-값의 "최소한 극단적" 정의는 깊은 맥락이며, 발생하지 않은 상황에서도 실험자가 무엇을 하려고 계획했는지에 따라 달라집니다.
역사

.jpg)


P-값 계산은 출생 시 인간의 성비를 계산한 1700년대까지 거슬러 올라가며,[24] 남녀 출산의 확률이 동일하다는 귀무 가설과 비교하여 통계적 유의성을 계산하는 데 사용되었다.존 아르부스노트는 1710년에 [25][26][27][28]이 문제를 연구했고 1629년부터 1710년까지 82년 동안 런던에서 출생 기록을 조사했다.매년 런던에서 태어난 남자들의 수가 여자들의 수를 넘어섰다.더 많은 남성 출산 또는 더 많은 여성 출산을 동등하게 고려할 때, 관측 결과의 확률은 1/282 또는 약 4,836,000,000,000,000,000,000,000,000,000, 즉 현대 용어로는 p-값이다.이것은 사라질 정도로 작은 것으로, 아르부스는 이것이 우연이 아니라 신의 섭리에 의한 것이라고 말하고 있다: "그로부터 그것은 우연이 아니라 예술이 지배한다."현대적 관점에서 그는 p = 1/282 유의 수준에서 남녀 출산 확률이 같다는 귀무 가설을 기각했다.Arbuthnot의 연구 및 기타 연구는 통계적 [30]유의성에 대한 추론의 첫 번째 예인 "… 유의성 검정의 첫 번째 사용…"[29] 및 "… 비모수 검정의 첫 번째 발표 보고서…"[26]로 인정된다. 특히 사인 검정의 세부사항 § 역사 참조.
같은 질문을 나중에 피에르-시몽 라플라스가 대신 모수 검정을 사용하여 이항 [31]분포를 사용하여 남성 출생아 수를 모델링했다.
1770년대에 라플레이스는 거의 50만 명의 출생아 통계를 고려했다.그 통계는 여자아이들에 비해 남자아이들이 더 많다는 것을 보여주었다.그는 p-값을 계산하여 초과가 실제적이지만 설명할 수 없는 효과라고 결론지었다.
p-값은 Karl Pearson의 카이 제곱 [32]검정에서 카이 제곱 분포를 사용하여 공식적으로 도입되었으며 대문자 [32]P로 표기되었습니다.현재 P로 표기된 카이 제곱 분포의 p-값은 (Elderton2 1902)에서 계산되었으며, (Pearson 1914, 페이지 xxxi-xxiii, 26-28, 표 X)에 수집되었다.II) : : 1914
통계에서 p-값의 사용은 Ronald [33][full citation needed]Fisher에 의해 대중화되었고,[34] 이것은 주제에 대한 그의 접근법에 중심적인 역할을 한다.피셔는 그의 영향력 있는 저서 Statistical Methods for Research Workers(1983)에서 통계적 유의성의 한계로 p = 0.05 즉, 우연히 초과될 확률 중 1을 제안했고, 이를 정규 분포(양 꼬리 검정)에 적용하여 두 표준 편차의 규칙을 도출했다.전략적 중요성(68-95-99.7 [35][note 3][36]규칙 참조).
그리고 나서 그는 엘더튼과 비슷한 가치표를 계산했지만, 중요한2 것은 §과 p의 역할을 뒤집었다.즉, 서로 다른 값인2 θ(및 자유도 n)에 대해 p를 계산하는 대신 특히 0.99, 0.98, 0.95, 0,90, 0.80, 0.70, 0.50, 0.30,[37] 0.20, 0.10, 0.05, 0.01을 산출하는 θ의2 값을 계산했습니다.이를 통해 θ의2 계산된 값을 컷오프와 비교할 수 있었고 p 값 자체를 계산하고 보고하는 대신 컷오프로서 p 값(특히 0.05, 0.02, 0.01)을 사용할 것을 권장했다.그 후 (Fisher & Yates 1938)에도 동일한 유형의 표가 작성되어 [36]접근방식이 강화되었다.
실험의 설계와 해석에 p-값의 적용에 대한 삽화로, 피셔는 그의 다음 책 The Design of Experiments (1935)에서 p-값의 전형적인 예인 티 시음 [38]실험을 제시했다.
Muriel Bristol(Muriel Bristol)이 차가 어떻게 준비되는지 맛으로 구분할 수 있다는 주장을 평가하기 위해, 그녀에게 8개의 컵을 차례로 제시했습니다: 4개는 편도로, 4개는 다른 방법으로 준비되었고, 각 컵의 준비를 결정하도록 요청했습니다(각 컵에 4개가 있다는 것을 알고 있습니다.이 경우, 귀무 가설은 특별한 능력이 없다는 것이었고, 테스트는 피셔의 정확한 테스트였으며, p-값은14 ) /0. 10. 피셔는 귀무 가설을 기각할 의향이 매우 낮았다.(실제 실험에서 브리스톨은 8개의 컵을 모두 정확하게 분류했다.)

피셔는 p = 0.05 임계값을 반복하고 그 근거를 설명하면서 다음과 같이 밝혔다.[39]
실험자는 이 표준에 도달하지 못한 모든 결과를 무시할 준비가 되어 있다는 점에서 5%를 표준 유의 수준으로 취하는 것이 일반적이고 편리하며, 이 방법을 통해 우연이 실험 기준에 가져온 변동의 대부분을 추가 논의에서 제거할 수 있다.삐치다
그는 또한 6개의 컵만 제시되었다면 (각 3개), 완벽한 분류는1/ [39](3)/ \ 105 유의성 수준을 충족하지 못했을 p-값만 산출했을 것이라는 점에 주목하면서 이 임계값을 실험 설계에 적용한다.또한 Fisher는 귀무 가설이 참이라고 가정할 때 최소한 데이터만큼 극단적인 값의 장기 비율인 p의 해석에 밑줄을 그었습니다.

이후 판에서 피셔는 과학에서 통계적 추론을 위한 p-값의 사용을 "수용 절차"라고 부르는 네이만-피어슨 방법과 명시적으로 비교했다.[40]Fisher는 5%, 2% 및 1%와 같은 고정 수준이 편리하지만 정확한 p-값을 사용할 수 있으며 추가 실험을 통해 증거의 강도를 수정할 수 있다고 강조합니다.이와는 대조적으로, 의사결정 절차는 명확한 결정을 필요로 하고, 되돌릴 수 없는 행동을 낳으며, 그 절차는 과학적 연구에 적용할 수 없는 오류 비용에 기초한다.
관련 지수
E-값은 다중 검정에서 귀무 가설이 [41]참이라고 가정할 때 실제로 관측된 검정 통계량만큼 극단적인 검정 통계량을 얻을 것으로 예상되는 예상 횟수에 해당합니다.E-값은 검정 횟수와 p-값의 곱입니다.
q-value는 양의 false discovery [42]rate에 관한 p-value의 아날로그입니다.잘못된 양수 [43]비율을 최소화하면서 통계적 검정력을 유지하기 위해 다중 가설 검정에서 사용됩니다.
방향 확률(pd)은 p-값의 [44]베이지안 수치입니다.이는 중앙값 부호의 후방 분포의 비율에 해당하며, 일반적으로 50%와 100% 사이에서 변화하며 효과가 양수 또는 음수인 확실성을 나타낸다.
「 」를 참조해 주세요.
메모들
- ^ 이탤릭체, 대문자와 하이픈은 다르다.예를 들어 AMA 스타일은 "P 값", APA 스타일은 "p 값",[1] 미국 통계 협회는 "p 값"을 사용합니다.
- ^ 결과의 통계적 유의성은 결과가 실제 관련성을 갖는다는 것을 의미하지 않는다.예를 들어, 약은 너무 작아서 흥미로울 수 없을 정도로 통계적으로 유의한 효과가 있을 수 있다.
- ^ 좀 더 구체적으로 말하면, p = 0.05는 정규 분포(양 꼬리 검정)의 경우 약 1.96 표준 편차에 해당하고, 2 표준 편차는 우연히 초과될 확률 또는 p ≤ 0.045에 해당합니다. Fisher는 이러한 근사치를 기록합니다.
레퍼런스
- ^ "ASA House Style" (PDF). Amstat News. American Statistical Association.
- ^ Aschwanden C (2015-11-24). "Not Even Scientists Can Easily Explain P-values". FiveThirtyEight. Archived from the original on 25 September 2019. Retrieved 11 October 2019.
- ^ a b c d e Wasserstein RL, Lazar NA (7 March 2016). "The ASA's Statement on p-Values: Context, Process, and Purpose". The American Statistician. 70 (2): 129–133. doi:10.1080/00031305.2016.1154108.
- ^ Hubbard R, Lindsay RM (2008). "Why P Values Are Not a Useful Measure of Evidence in Statistical Significance Testing". Theory & Psychology. 18 (1): 69–88. doi:10.1177/0959354307086923. S2CID 143487211.
- ^ Munafò MR, Nosek BA, Bishop DV, Button KS, Chambers CD, du Sert NP, et al. (January 2017). "A manifesto for reproducible science". Nature Human Behaviour. 1: 0021. doi:10.1038/s41562-016-0021. PMC 7610724. PMID 33954258. S2CID 6326747.
- ^ Bhattacharya B, Habtzghi D (2002). "Median of the p value under the alternative hypothesis". The American Statistician. 56 (3): 202–6. doi:10.1198/000313002146. S2CID 33812107.
- ^ Hung HM, O'Neill RT, Bauer P, Köhne K (March 1997). "The behavior of the P-value when the alternative hypothesis is true". Biometrics (Submitted manuscript). 53 (1): 11–22. doi:10.2307/2533093. JSTOR 2533093. PMID 9147587.
- ^ a b Head ML, Holman L, Lanfear R, Kahn AT, Jennions MD (March 2015). "The extent and consequences of p-hacking in science". PLOS Biology. 13 (3): e1002106. doi:10.1371/journal.pbio.1002106. PMC 4359000. PMID 25768323.
- ^ Simonsohn U, Nelson LD, Simmons JP (November 2014). "p-Curve and Effect Size: Correcting for Publication Bias Using Only Significant Results". Perspectives on Psychological Science. 9 (6): 666–681. doi:10.1177/1745691614553988. PMID 26186117. S2CID 39975518.
- ^ Nuzzo R (February 2014). "Scientific method: statistical errors". Nature. 506 (7487): 150–152. Bibcode:2014Natur.506..150N. doi:10.1038/506150a. PMID 24522584.
- ^ Colquhoun D (November 2014). "An investigation of the false discovery rate and the misinterpretation of p-values". Royal Society Open Science. 1 (3): 140216. arXiv:1407.5296. Bibcode:2014RSOS....140216C. doi:10.1098/rsos.140216. PMC 4448847. PMID 26064558.
- ^ Lee DK (December 2016). "Alternatives to P value: confidence interval and effect size". Korean Journal of Anesthesiology. 69 (6): 555–562. doi:10.4097/kjae.2016.69.6.555. PMC 5133225. PMID 27924194.
- ^ Ranstam J (August 2012). "Why the P-value culture is bad and confidence intervals a better alternative". Osteoarthritis and Cartilage. 20 (8): 805–808. doi:10.1016/j.joca.2012.04.001. PMID 22503814.
- ^ Perneger TV (May 2001). "Sifting the evidence. Likelihood ratios are alternatives to P values". BMJ. 322 (7295): 1184–1185. doi:10.1136/bmj.322.7295.1184. PMC 1120301. PMID 11379590.
- ^ Royall R (2004). "The Likelihood Paradigm for Statistical Evidence". The Nature of Scientific Evidence. pp. 119–152. doi:10.7208/chicago/9780226789583.003.0005. ISBN 9780226789576.
- ^ Schimmack U (30 April 2015). "Replacing p-values with Bayes-Factors: A Miracle Cure for the Replicability Crisis in Psychological Science". Replicability-Index. Retrieved 7 March 2017.
- ^ Marden JI (December 2000). "Hypothesis Testing: From p Values to Bayes Factors". Journal of the American Statistical Association. 95 (452): 1316–1320. doi:10.2307/2669779. JSTOR 2669779.
- ^ Stern HS (16 February 2016). "A Test by Any Other Name: P Values, Bayes Factors, and Statistical Inference". Multivariate Behavioral Research. 51 (1): 23–29. doi:10.1080/00273171.2015.1099032. PMC 4809350. PMID 26881954.
- ^ Murtaugh PA (March 2014). "In defense of P values". Ecology. 95 (3): 611–617. doi:10.1890/13-0590.1. PMID 24804441.
- ^ Aschwanden C (7 March 2016). "Statisticians Found One Thing They Can Agree On: It's Time To Stop Misusing P-Values". FiveThirtyEight.
- ^ Amrhein V, Korner-Nievergelt F, Roth T (2017). "The earth is flat (p > 0.05): significance thresholds and the crisis of unreplicable research". PeerJ. 5: e3544. doi:10.7717/peerj.3544. PMC 5502092. PMID 28698825.
- ^ Amrhein V, Greenland S (January 2018). "Remove, rather than redefine, statistical significance". Nature Human Behaviour. 2 (1): 4. doi:10.1038/s41562-017-0224-0. PMID 30980046. S2CID 46814177.
- ^ Colquhoun D (December 2017). "The reproducibility of research and the misinterpretation of p-values". Royal Society Open Science. 4 (12): 171085. doi:10.1098/rsos.171085. PMC 5750014. PMID 29308247.
- ^ Brian E, Jaisson M (2007). "Physico-Theology and Mathematics (1710–1794)". The Descent of Human Sex Ratio at Birth. Springer Science & Business Media. pp. 1–25. ISBN 978-1-4020-6036-6.
- ^ Arbuthnot J (1710). "An argument for Divine Providence, taken from the constant regularity observed in the births of both sexes" (PDF). Philosophical Transactions of the Royal Society of London. 27 (325–336): 186–190. doi:10.1098/rstl.1710.0011. S2CID 186209819.
- ^ a b Conover WJ (1999). "Chapter 3.4: The Sign Test". Practical Nonparametric Statistics (Third ed.). Wiley. pp. 157–176. ISBN 978-0-471-16068-7.
- ^ Sprent P (1989). Applied Nonparametric Statistical Methods (Second ed.). Chapman & Hall. ISBN 978-0-412-44980-2.
- ^ Stigler SM (1986). The History of Statistics: The Measurement of Uncertainty Before 1900. Harvard University Press. pp. 225–226. ISBN 978-0-67440341-3.
- ^ Bellhouse P (2001). "John Arbuthnot". In Heyde CC, Seneta E (eds.). Statisticians of the Centuries. Springer. pp. 39–42. ISBN 978-0-387-95329-8.
- ^ Hald A (1998). "Chapter 4. Chance or Design: Tests of Significance". A History of Mathematical Statistics from 1750 to 1930. Wiley. p. 65.
- ^ Stigler SM (1986). The History of Statistics: The Measurement of Uncertainty Before 1900. Harvard University Press. p. 134. ISBN 978-0-67440341-3.
- ^ a b Pearson K (1900). "On the criterion that a given system of deviations from the probable in the case of a correlated system of variables is such that it can be reasonably supposed to have arisen from random sampling" (PDF). Philosophical Magazine. Series 5. 50 (302): 157–175. doi:10.1080/14786440009463897.
- ^ Inman 2004. 오류:: 2004
- ^ Hubbard R, Bayarri MJ (2003), "Confusion Over Measures of Evidence (p′s) Versus Errors (α′s) in Classical Statistical Testing", The American Statistician, 57 (3): 171–178 [p. 171], doi:10.1198/0003130031856, S2CID 55671953
- ^ 피셔 1925, 47페이지, 3장 배포.
- ^ a b 2012년 달랄, 주 31: 왜 P=0.05인가?
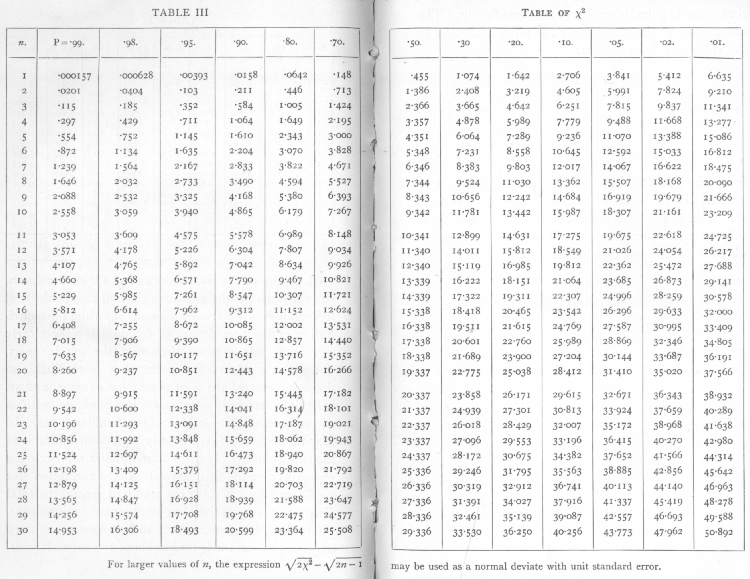
- ^ 피셔 1925, 78-79페이지, 98, IV장. 적합도, 독립성 및 균질성 테스트, § 표2, 표 III. χ의2 표
- ^ 피셔 1971, II정신-물리 실험으로 설명되는 실험의 원리.
- ^ a b 피셔 1971, 섹션 7중요성의 검정.
- ^ Fisher 1971, 섹션 12.1 과학적 추론 및 승인 절차.
- ^ "Definition of E-value". National Institutes of Health.
- ^ Storey JD (2003). "The positive false discovery rate: a Bayesian interpretation and the q-value". The Annals of Statistics. 31 (6): 2013–2035. doi:10.1214/aos/1074290335.
- ^ Storey JD, Tibshirani R (August 2003). "Statistical significance for genomewide studies". Proceedings of the National Academy of Sciences of the United States of America. 100 (16): 9440–9445. Bibcode:2003PNAS..100.9440S. doi:10.1073/pnas.1530509100. PMC 170937. PMID 12883005.
- ^ Makowski D, Ben-Shachar MS, Chen SH, Lüdecke D (10 December 2019). "Indices of Effect Existence and Significance in the Bayesian Framework". Frontiers in Psychology. 10: 2767. doi:10.3389/fpsyg.2019.02767. PMC 6914840. PMID 31920819.
{kind=link}
추가 정보
- Denworth L (October 2019). "A Significant Problem: Standard scientific methods are under fire. Will anything change?". Scientific American. 321 (4): 62–67 (63).
The use of p values for nearly a century [since 1925] to determine statistical significance of experimental results has contributed to an illusion of certainty and [to] reproducibility crises in many scientific fields. There is growing determination to reform statistical analysis... Some [researchers] suggest changing statistical methods, whereas others would do away with a threshold for defining "significant" results.
- Elderton WP (1902). "Tables for Testing the Goodness of Fit of Theory to Observation". Biometrika. 1 (2): 155–163. doi:10.1093/biomet/1.2.155.
- Fisher RA (1925). Statistical Methods for Research Workers. Edinburgh, Scotland: Oliver & Boyd. ISBN 978-0-05-002170-5.
- Fisher RA (1971) [1935]. The Design of Experiments (9th ed.). Macmillan. ISBN 978-0-02-844690-5.
- Fisher RA, Yates F (1938). Statistical tables for biological, agricultural and medical research. London, England.
- Stigler SM (1986). The history of statistics : the measurement of uncertainty before 1900. Cambridge, Mass: Belknap Press of Harvard University Press. ISBN 978-0-674-40340-6.
- Hubbard R, Armstrong JS (2006). "Why We Don't Really Know What Statistical Significance Means: Implications for Educators" (PDF). Journal of Marketing Education. 28 (2): 114–120. doi:10.1177/0273475306288399. hdl:2092/413. S2CID 34729227. Archived from the original (PDF) on May 18, 2006.
- Hubbard R, Lindsay RM (2008). "Why P Values Are Not a Useful Measure of Evidence in Statistical Significance Testing" (PDF). Theory & Psychology. 18 (1): 69–88. doi:10.1177/0959354307086923. S2CID 143487211. Archived from the original (PDF) on 2016-10-21. Retrieved 2015-08-28.
- Stigler S (December 2008). "Fisher and the 5% level". Chance. 21 (4): 12. doi:10.1007/s00144-008-0033-3.
- Dallal GE (2012). The Little Handbook of Statistical Practice.
- Biau DJ, Jolles BM, Porcher R (March 2010). "P value and the theory of hypothesis testing: an explanation for new researchers". Clinical Orthopaedics and Related Research. 468 (3): 885–892. doi:10.1007/s11999-009-1164-4. PMC 2816758. PMID 19921345.
- Reinhart A (2015). Statistics Done Wrong: The Woefully Complete Guide. No Starch Press. p. 176. ISBN 978-1593276201.
외부 링크
- 다양한 특정 검정(chi-square, Fisher's F-검정 등)에 대한 무료 온라인 p-값 계산기.
- p-값의 수치값이 테스트 대상 가설의 진실 또는 거짓에 대해 상당히 오해의 소지가 있는 인상을 줄 수 있는 Java 애플릿을 포함하여 p-값을 이해한다.
- StatQuest: P Values, YouTube에서 명확하게 설명
- StatQuest: YouTube에서의 P-값 함정 및 전력 계산
- 과학은 깨지지 않는다 - p-값을 조작하는 방법과 이를 시각화하는 대화형 도구에 대한 기사.