단백질 2차 구조
Protein secondary structure
단백질 2차 구조는 단백질의 국소 세그먼트의 3차원 형태다. 베타 턴과 오메가 루프도 발생하지만 가장 일반적인 두 가지 2차 구조 요소는 알파 나선과 베타 시트다. 이차 구조 요소는 단백질이 3차원 3차원으로 접히기 전에 일반적으로 중간의 형태로 자연적으로 형성된다.
2차 구조는 펩타이드 백본에 있는 아미노 수소와 카복실 산소 원자 사이의 수소 결합 패턴에 의해 공식적으로 정의된다. 이차 구조는 올바른 수소 결합 여부에 관계없이 라마찬드란 플롯의 특정 영역에서 백본 이음각의 정규 패턴을 기반으로 정의할 수 있다.
2차 구조의 개념은 1952년 스탠포드 대학에서 Kaj Ulrik Linderström-Lang에 의해 처음 도입되었다.[1][2] 핵산과 같은 다른 유형의 생물폴리머도 2차 구조를 가지고 있다.
종류들
| 지오메트리 속성 | α-helix | 3나선10 | π-helix |
|---|---|---|---|
| 턴당 잔류물 | 3.6 | 3.0 | 4.4 |
| 잔류물당번역 | 1.5 å(0.15 nm) | 2.0 å(0.20 nm) | 1.1 å(0.11 nm) |
| 나선 반지름 | 2.3 å(0.23 nm) | 1.9 å(0.19 nm) | 2.8 å(0.28 nm) |
| 피치 | 5.4 å(0.54 nm) | 6.0 å(0.60 nm) | 4.8 å(0.48 nm) |
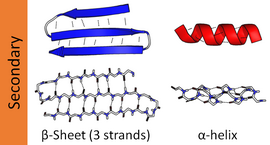
가장 흔한 이차 구조물은 알파 나선과 베타 시트다. 3나선10, π나선 등 다른 나선은 활력적으로 유리한 수소결합 패턴을 갖는 것으로 계산되지만 나선의 중심에서 등뼈 패킹이 좋지 않아 α나선 끝부분을 제외한 자연 단백질에서는 거의 관찰되지 않는다. 폴리프로라인나선나선이나 알파시트 같은 다른 확장된 구조물은 고유상태 단백질에서는 드물지만 중요한 단백질 접힘 매개체로 가정되는 경우가 많다. 팽팽한 턴과 느슨하고 유연한 루프는 보다 "일반적인" 이차 구조 요소를 연결한다. 무작위 코일은 참된 2차 구조가 아니라 규칙적인 2차 구조의 부재를 나타내는 순응 등급이다.
아미노산은 다양한 2차 구조 원소를 형성하는 능력에 있어 다양하다. 프롤라인과 글리신은 α 나선 등뼈 순응의 규칙성을 교란하기 때문에 때때로 "헬릭스 차단기"로 알려져 있지만, 둘 다 비정상적인 순응 능력을 가지고 있으며 일반적으로 교대로 발견된다. Amino acids that prefer to adopt helical conformations in proteins include methionine, alanine, leucine, glutamate and lysine ("MALEK" in amino-acid 1-letter codes); by contrast, the large aromatic residues (tryptophan, tyrosine and phenylalanine) and Cβ-branched amino acids (isoleucine, valine, and threonine) prefer to adopt β-strand conformations그러나 이러한 선호도는 시퀀스만으로 2차 구조를 신뢰할 수 있는 예측 방법을 만들기에 충분하지 않다.
저주파 집단 진동은 단백질 내의 국소 경직성에 민감하다고 생각되어 베타 구조가 알파나 질서 정연한 단백질보다 일반적으로 더 경직된 것으로 밝혀진다.[5][6] 중성자 산란 측정은 베타-바렐 단백질 GFP의 2차 구조의 집단 운동과 최대 1THz의 스펙트럼 특징을 직접 연결했다.[7]
2차 구조물의 수소 결합 패턴이 크게 왜곡될 수 있어 2차 구조물의 자동 판정이 어렵다. 공식적으로 단백질 2차 구조를 정의하는 몇 가지 방법(예: DSSP,[8] DEFING, STRIDE,[9][10] ScrewFit,[11] SST[12])이 있다.
DSSP구분

단백질 2차 구조 사전은 짧은 DSSP로 단백질 2차 구조를 단일 문자 코드로 설명하는 데 일반적으로 사용된다. 이차 구조는 (어떤 단백질 구조가 실험적으로 결정되기 전) 1951년 폴링 등이 처음 제안한 것과 같이 수소 결합 패턴을 기반으로 할당된다. DSSP가 정의하는 이차 구조에는 다음과 같은 8가지 유형이 있다.
- G = 3회전 나선(3나선10) 최소 길이 3의 잔류물.
- H = 4회전나선(α나선) 최소 길이 4개 잔여물.
- I = 5회전 나선형(ππ나선형) 최소 길이 5개 잔여물.
- T = 수소 접합 턴(3, 4 또는 5 턴)
- E = 병렬로 확장된 스트랜드 및/또는 반병렬 β-시트 순응. 최소 길이 2의 잔류물.
- B = 격리된 β-브릿지의 잔류물(단일 쌍 β-시트 수소 결합 형성)
- S = 벤딩(비수소-본드 기반 유일한 할당).
- C = 코일(위의 순응에 포함되지 않은 값).
'코일'은 흔히 '(공간), C(코일) 또는 '–'(대시)로 표기된다. 나선형(G, H, I)과 시트 순응은 모두 길이가 적당해야 한다. 이는 1차 구조물에 인접한 2개의 잔류물이 동일한 수소 본딩 패턴을 형성해야 함을 의미한다. 나선형 또는 시트 수소 결합 패턴이 너무 짧으면 각각 T 또는 B로 지정된다. 다른 단백질 2차 구조 할당 범주(샤프 턴, 오메가 루프 등)가 존재하지만 덜 자주 사용된다.
이차 구조는 수소 결합에 의해 정의되기 때문에 수소 결합의 정확한 정의가 중요하다. 2차 구조에 대한 표준 수소 본드 정의는 순수 정전기 모델인 DSSP의 정의다. 카보닐 탄소와 산소에 각각 ±q1 ± 0.42e의 전하를, 아미드 수소와 질소에 각각 ±q2 0 0.20e의 전하를 할당한다. 정전기 에너지는

DSSP에 따르면 E가 -0.5kcal/mol(-2.1kJ/mol) 미만인 경우에만 수소 본드가 존재한다고 한다. DSSP 공식은 물리 수소 본드 에너지의 비교적 조잡한 근사치지만, 일반적으로 이차 구조를 정의하는 도구로 받아들여진다.
SST[12] 분류
SST는 최소 메시지 길이(MML) 추론의 섀넌 정보 기준을 이용하여 단백질 좌표 데이터에 이차 구조를 할당하는 베이시안 방식이다. SST는 이차 구조의 배정을 주어진 단백질 좌표 데이터를 설명(압축)하려는 잠재적 가설로 취급한다. 가장 좋은 2차 구조 배정은 주어진 단백질 좌표의 좌표를 가장 경제적인 방법으로 설명(압축)할 수 있는 것으로, 2차 구조의 추론을 무손실 데이터 압축과 연결시킬 수 있다는 것이 핵심 생각이다. SST는 단백질 체인을 다음 할당 유형과 관련된 영역으로 정확하게 기술한다.[13]
- E = β-완성 시트의 (확장) 가닥
- G = 오른손잡이 3나선10
- H = 오른손 α-헬릭스
- I = 오른손 π-헬릭스
- g = 왼손 3나선10
- h = 왼손잡이 α-헬릭스
- i = 왼손 π-헬릭스
- 3 = 3-라이크10 턴
- 4 = α와 같은 턴
- 5 = π과 같은 턴
- T = 지정되지 않은 턴
- C = 코일
- - = 미지정 잔여물
SST는 표준 α-헬리케인에 대한 α-헬리케이트와 3개의10 헬리컬 캡을 검출하고, 다양한 확장된 가닥을 일치 β-완성 시트로 자동 조립한다. 해부된 2차 구조 요소의 읽기 가능한 출력물과 할당된 2차 구조 요소를 개별적으로 시각화하기 위한 해당 PyMol-loadable 스크립트를 제공한다.
실험결정
생물폴리머의 대략적인 2차 구조 함량(예: "이 단백질은 α-헬릭스 40%, β-시트 20%")은 분광학적으로 추정할 수 있다.[14] 단백질의 경우, 일반적인 방법은 극초자외선(far-UV, 170–250nm) 원형 이분법이다. 208 nm와 222 nm에서 두 배 이상의 분명한 최소값은 α-헬리컬 구조를 나타내며, 204 nm 또는 217 nm의 단일 최소값은 각각 무작위 코일 또는 β-시트 구조를 반영한다. 수소결합으로 인한 아미드 그룹의 결합 진동 차이를 감지하는 적외선 분광법도 덜 보편적인 방법이다. 마지막으로, 이차 구조 내용은 초기에 지정되지 않은 NMR 스펙트럼의 화학적 변화를 사용하여 정확하게 추정할 수 있다.[15]
예측
아미노 시퀀스에서만 단백질 3차 구조를 예측하는 것은 매우 어려운 문제지만(단백질 구조 예측 참조), 보다 간단한 2차 구조 정의를 사용하는 것이 더 다루기 쉽다.
이차 구조 예측의 초기 방법은 나선, 시트 또는 무작위 코일의 세 가지 우위 상태를 예측하는 것으로 제한되었다. 이 방법들은 개별 아미노산의 나선형 또는 시트형성 예언에 기초했으며, 때로는 2차 구조 원소를 형성하는 자유 에너지를 추정하는 규칙과 결합되기도 했다. 아미노산 염기서열에서 단백질 2차 구조를 예측하기 위해 널리 사용되는 첫 번째 기술은 Chu-Fasman 방법과[16][17][18] GOR 방법이었다.[19] 이러한 방법은 잔여물이 채택되는 세 상태(헬릭스/시트/코일) 중 어느 상태(헬릭스/시트/코일)를 예측하는 데 있어 최대 60%의 정확도를 달성한다고 주장했지만, 나중에 블라인드 컴퓨팅 평가에서 실제 정확도가 훨씬 낮았다.[20]
다중 시퀀스 정렬을 이용하여 정확도를 유의하게 증가(약 80%까지)했다. 진화를 통해 한 위치에서 발생하는 아미노산(및 그 근처에 일반적으로 양쪽에 7개까지 잔류물)의 전체 분포를 알면 해당 위치 근처의 구조 경향을 훨씬 잘 파악할 수 있다.[21][22] 예를 들어, 주어진 단백질은 주어진 위치에 글리신(glycine)을 가지고 있을 수 있으며, 그 자체로 그곳의 무작위 코일을 암시할 수 있다. 그러나, 다중 시퀀스 정렬은 거의 10억 년의 진화에 걸쳐 95%의 호몰로겐 단백질이 헬릭스 선호 아미노산이 그 위치(및 인근 위치)에서 발생한다는 것을 밝혀낼 수 있다. 더욱이 그 위치 및 인근 위치에서의 평균 친수성을 검사함으로써, 동일한 정렬은 α-헬릭스(α-헬릭스)와 일치하는 잔류 용매 접근성의 패턴을 제안할 수도 있다. 이러한 요소들을 종합하면, 본래의 단백질의 글리신이 무작위 코일이 아닌 α-헬리컬 구조를 채택하고 있음을 암시할 수 있다. 신경망, 숨겨진 마르코프 모델, 지원 벡터 머신 등 3가지 상태 예측을 형성하기 위해 이용 가능한 모든 데이터를 결합하는 여러 가지 방법이 사용된다. 현대의 예측 방법 또한 모든 위치에서 예측에 대한 신뢰 점수를 제공한다.
이차 구조 예측 방법은 CASP(Critical Assessment of protecture expective) 실험에 의해 평가되었고, EVA(benchmark)에 의해 지속적으로 벤치마킹되었다. 이러한 테스트를 바탕으로 가장 정확한 방법은 Psipred, SAM,[23] PORER,[24] PROP,[25] SABLE이었다.[26] 개선의 주요 영역은 β-스트랜드의 예측으로 보인다. β-스트랜드로 자신 있게 예측된 잔류물은 그럴 가능성이 높지만, 방법은 일부 β-스트랜드 세그먼트(부정음)를 간과하기 쉽다. 예측이 벤치마킹되는 PDB 구조에 2차 구조 클래스(헬릭스/스트랜드/코일)를 할당하는 표준 방법(DSSP)의 특성 때문에 전체적으로 예측 정확도가 90%까지 상한이 있을 수 있다.[27]
정확한 2차 구조 예측은 가장 단순한 (동질 모델링) 경우를 제외한 모든 사례에서 3차 구조 예측의 핵심 요소다. 예를 들어, 자신 있게 예측한 6개의 2차 구조 요소 βαββαβαβαββ는 페레독신 접종의 시그니처다.[28]
적용들
단백질과 핵산 이차 구조는 모두 다중 시퀀스 정렬을 돕는 데 사용될 수 있다. 이러한 정렬은 단순한 시퀀스 정보 외에 2차 구조 정보를 포함함으로써 보다 정확하게 이루어질 수 있다. 염기쌍은 염기쌍이 염기서열보다 훨씬 더 보존력이 높기 때문에 RNA에서는 때때로 덜 유용하다. 1차 구조가 조정 불가능한 단백질 사이의 먼 관계는 2차 구조에 의해 때때로 발견될 수 있다.[21]
α-헬리케스는 자연 단백질에서 β-균드보다 더 안정적이고 돌연변이에 강하며 설계가 가능한 것으로 밝혀져 [29]기능적 전α 단백질을 설계하는 것이 나선과 가닥을 모두 가진 단백질을 설계하는 것보다 쉬울 가능성이 높은 것으로 최근 실험적으로 확인되었다.[30]
참고 항목
참조
- ^ Linderstrøm-Lang KU (1952). Lane Medical Lectures: Proteins and Enzymes. Stanford University Press. p. 115. ASIN B0007J31SC.
- ^ Schellman JA, Schellman CG (1997). "Kaj Ulrik Linderstrøm-Lang (1896–1959)". Protein Sci. 6 (5): 1092–100. doi:10.1002/pro.5560060516. PMC 2143695. PMID 9144781.
He had already introduced the concepts of the primary, secondary, and tertiary structure of proteins in the third Lane Lecture (Linderstram-Lang, 1952)
- ^ Steven Bottomley (2004). "Interactive Protein Structure Tutorial". Archived from the original on March 1, 2011. Retrieved January 9, 2011.
- ^ Schulz, G. E. (Georg E.), 1939- (1979). Principles of protein structure. Schirmer, R. Heiner, 1942-. New York: Springer-Verlag. ISBN 0-387-90386-0. OCLC 4498269.
{{cite book}}: CS1 maint : 복수이름 : 작성자 목록(링크) - ^ Perticaroli S, Nickels JD, Ehlers G, O'Neill H, Zhang Q, Sokolov AP (October 2013). "Secondary structure and rigidity in model proteins". Soft Matter. 9 (40): 9548–56. Bibcode:2013SMat....9.9548P. doi:10.1039/C3SM50807B. PMID 26029761.
- ^ Perticaroli S, Nickels JD, Ehlers G, Sokolov AP (June 2014). "Rigidity, secondary structure, and the universality of the boson peak in proteins". Biophysical Journal. 106 (12): 2667–74. Bibcode:2014BpJ...106.2667P. doi:10.1016/j.bpj.2014.05.009. PMC 4070067. PMID 24940784.
- ^ Nickels JD, Perticaroli S, O'Neill H, Zhang Q, Ehlers G, Sokolov AP (2013). "Coherent neutron scattering and collective dynamics in the protein, GFP". Biophys. J. 105 (9): 2182–87. Bibcode:2013BpJ...105.2182N. doi:10.1016/j.bpj.2013.09.029. PMC 3824694. PMID 24209864.
- ^ Kabsch W, Sander C (Dec 1983). "Dictionary of protein secondary structure: pattern recognition of hydrogen-bonded and geometrical features". Biopolymers. 22 (12): 2577–637. doi:10.1002/bip.360221211. PMID 6667333. S2CID 29185760.
- ^ Richards FM, Kundrot CE (1988). "Identification of structural motifs from protein coordinate data: secondary structure and first-level supersecondary structure". Proteins. 3 (2): 71–84. doi:10.1002/prot.340030202. PMID 3399495. S2CID 29126855.
- ^ Frishman D, Argos P (Dec 1995). "Knowledge-based protein secondary structure assignment" (PDF). Proteins. 23 (4): 566–79. CiteSeerX 10.1.1.132.9420. doi:10.1002/prot.340230412. PMID 8749853. S2CID 17487756. Archived from the original (PDF) on 2010-06-13.
- ^ Calligari PA, Kneller GR (December 2012). "ScrewFit: combining localization and description of protein secondary structure". Acta Crystallographica Section D. 68 (Pt 12): 1690–3. doi:10.1107/s0907444912039029. PMID 23151634.
- ^ a b Konagurthu AS, Lesk AM, Allison L (Jun 2012). "Minimum message length inference of secondary structure from protein coordinate data". Bioinformatics. 28 (12): i97–i105. doi:10.1093/bioinformatics/bts223. PMC 3371855. PMID 22689785.
- ^ "SST web server". Retrieved 17 April 2018.
- ^ Pelton JT, McLean LR (2000). "Spectroscopic methods for analysis of protein secondary structure". Anal. Biochem. 277 (2): 167–76. doi:10.1006/abio.1999.4320. PMID 10625503.
- ^ Meiler J, Baker D (2003). "Rapid protein fold determination using unassigned NMR data". Proc. Natl. Acad. Sci. U.S.A. 100 (26): 15404–09. Bibcode:2003PNAS..10015404M. doi:10.1073/pnas.2434121100. PMC 307580. PMID 14668443.
- ^ Chou PY, Fasman GD (Jan 1974). "Prediction of protein conformation". Biochemistry. 13 (2): 222–45. doi:10.1021/bi00699a002. PMID 4358940.
- ^ Chou PY, Fasman GD (1978). "Empirical predictions of protein conformation". Annual Review of Biochemistry. 47: 251–76. doi:10.1146/annurev.bi.47.070178.001343. PMID 354496.
- ^ Chou PY, Fasman GD (1978). "Prediction of the secondary structure of proteins from their amino acid sequence". Advances in Enzymology and Related Areas of Molecular Biology. Advances in Enzymology - and Related Areas of Molecular Biology. Vol. 47. pp. 45–148. doi:10.1002/9780470122921.ch2. ISBN 9780470122921. PMID 364941.
- ^ Garnier J, Osguthorpe DJ, Robson B (March 1978). "Analysis of the accuracy and implications of simple methods for predicting the secondary structure of globular proteins". Journal of Molecular Biology. 120 (1): 97–120. doi:10.1016/0022-2836(78)90297-8. PMID 642007.
- ^ Kabsch W, Sander C (May 1983). "How good are predictions of protein secondary structure?". FEBS Letters. 155 (2): 179–82. doi:10.1016/0014-5793(82)80597-8. PMID 6852232. S2CID 41477827.
- ^ a b Simossis VA, Heringa J (Aug 2004). "Integrating protein secondary structure prediction and multiple sequence alignment". Current Protein & Peptide Science. 5 (4): 249–66. doi:10.2174/1389203043379675. PMID 15320732.
- ^ Pirovano W, Heringa J (2010). "Protein secondary structure prediction". Data Mining Techniques for the Life Sciences. Methods in Molecular Biology. Vol. 609. pp. 327–48. doi:10.1007/978-1-60327-241-4_19. ISBN 978-1-60327-240-7. PMID 20221928.
- ^ Karplus K (2009). "SAM-T08, HMM-based protein structure prediction". Nucleic Acids Res. 37 (Web Server issue): W492–97. doi:10.1093/nar/gkp403. PMC 2703928. PMID 19483096.
- ^ Pollastri G, McLysaght A (2005). "Porter: a new, accurate server for protein secondary structure prediction". Bioinformatics. 21 (8): 1719–20. doi:10.1093/bioinformatics/bti203. PMID 15585524.
- ^ Yachdav G, Kloppmann E, Kajan L, Hecht M, Goldberg T, Hamp T, Hönigschmid P, Schafferhans A, Roos M, Bernhofer M, Richter L, Ashkenazy H, Punta M, Schlessinger A, Bromberg Y, Schneider R, Vriend G, Sander C, Ben-Tal N, Rost B (2014). "PredictProtein—an open resource for online prediction of protein structural and functional features". Nucleic Acids Res. 42 (Web Server issue): W337–43. doi:10.1093/nar/gku366. PMC 4086098. PMID 24799431.
- ^ Adamczak R, Porollo A, Meller J (2005). "Combining prediction of secondary structure and solvent accessibility in proteins". Proteins. 59 (3): 467–75. doi:10.1002/prot.20441. PMID 15768403. S2CID 13267624.
- ^ Kihara D (Aug 2005). "The effect of long-range interactions on the secondary structure formation of proteins". Protein Science. 14 (8): 1955–963. doi:10.1110/ps.051479505. PMC 2279307. PMID 15987894.
- ^ Qi Y, Grishin NV (2005). "Structural classification of thioredoxin-like fold proteins" (PDF). Proteins. 58 (2): 376–88. CiteSeerX 10.1.1.644.8150. doi:10.1002/prot.20329. PMID 15558583. S2CID 823339.
Since the fold definition should include only the core secondary structural elements that are present in the majority of homologs, we define the thioredoxin-like fold as a two-layer α/β sandwich with the βαβββα secondary-structure pattern.
- ^ Abrusan G, Marsh JA (2016). "Alpha helices are more robust to mutations than beta strands". PLOS Computational Biology. 12 (12): e1005242. Bibcode:2016PLSCB..12E5242A. doi:10.1371/journal.pcbi.1005242. PMC 5147804. PMID 27935949.
- ^ Rocklin GJ, et al. (2017). "Global analysis of protein folding using massively parallel design, synthesis, and testing". Science. 357 (6347): 168–175. Bibcode:2017Sci...357..168R. doi:10.1126/science.aan0693. PMC 5568797. PMID 28706065.
추가 읽기
- Branden C, Author J (1999). Introduction to protein structure (2nd ed.). New York: Garland Science. ISBN 978-0815323051.
{{cite book}}:author=일반 이름 포함(도움말) - Pauling L, Corey RB (1951). "Configurations of Polypeptide Chains With Favored Orientations Around Single Bonds: Two New Pleated Sheets". Proc. Natl. Acad. Sci. U.S.A. 37 (11): 729–40. Bibcode:1951PNAS...37..729P. doi:10.1073/pnas.37.11.729. PMC 1063460. PMID 16578412. (원래 베타 시트 준수 문서)
- 폴링 L, 코리 RB, 브랜슨은 HR(1951년)."는 폴리 펩타이드 사슬의 단백질의 구조물이다. 두hydrogen-bonded 나선형 구성".Proc.Natl.로. Sci. 미국 37(4):205–11.Bibcode:1951PNAS...37..205P. doi:10.1073/pnas.37.4.205.PMC1063337.PMID 14816373.(alpha-과 pi-helix 입체 배열, 이후 그들은 310{\displaystyle 3_{10}}나선 것은 불가능할 것으로 전망했다.).
외부 링크
- NetSurfP – 이차 구조 및 표면 접근성 예측 변수
- PROF
- 나사핏
- PSSpred 단백질 2차 구조 예측을 위한 다신경망 훈련 프로그램
- 한 번의 클릭으로 20개의 다른 2차 구조 예측 변수를 실행할 수 있는 Genesilico Metaserver Metaserver
- SST 웹 서버: 정보-이론적(압축 기반) 이차 구조 할당.


.png){kind=link}
.png){kind=link}