코드 페이지
Code page컴퓨팅에서 코드 페이지는 문자 부호화이며, 따라서 인쇄 가능한 문자와 제어 문자의 집합과 고유 번호와의 특정 연관성이다.일반적으로 각 숫자는 1바이트의 이진수 값을 나타냅니다.(일부 컨텍스트에서는 이러한 용어가 보다 정확하게 사용되고 있습니다.「문자 인코딩」 「문자 세트, 문자 맵, 코드 페이지」를 참조해 주세요).
"코드 페이지"라는 용어는 IBM의 EBCDIC 기반 메인프레임 [1]시스템에서 유래했지만, Microsoft,[2] SAP 및 Oracle[3] Corporation이 이 용어를 사용하는 몇 안 되는 벤더 중 하나입니다.대부분의 벤더는 자신의 문자 집합을 이름으로 식별합니다.(IBM과 같이) 문자 집합이 너무 많은 경우 숫자를 통해 문자 집합을 식별하는 것이 이를 구별하는 편리한 방법입니다.원래 코드 페이지 번호는 IBM 표준 문자 집합 [4][5][6]설명서의 페이지 번호를 참조하는 것으로, 오랫동안 유지되지 않았던 조건입니다.코드 페이지 시스템을 사용하는 벤더는 다른 이름으로 더 잘 알려진 경우에도 자체 코드 페이지 번호를 문자 인코딩에 할당합니다. 예를 들어 UTF-8에는 IBM에서 1208 페이지 번호, 마이크로소프트에서 65001 페이지 번호, SAP에서 4110 페이지 번호가 할당되어 있습니다.
Hewlett-Packard는 HP-UX 운영체제 및 프린터용 PCL(Printer Command[7] Language) 프로토콜에서 동일한 개념을 사용합니다(HP 프린터용인지 여부에 관계없이).단, 용어는 다릅니다.다른 사람들은 문자 집합을, HP는 기호 집합을, IBM 또는 Microsoft는 코드 페이지를, HP는 기호 집합 코드를 각각 부릅니다.HP는 자체 문자 집합과 다른 공급업체의 문자 집합을 모두 인코딩하기 위해 각각 연관된 기호 집합 코드를 가진 일련의 기호 [8][9]집합을 개발했다.
다수의 문자 집합으로 인해 많은 벤더가 Unicode를 권장하고 있습니다.
코드 페이지 번호 부여 시스템
IBM은 컴퓨터 시스템 또는 컴퓨터 시스템 집합에서 발생할 수 있는 각 문자 인코딩에 16비트 번호를 체계적으로 할당하는 개념을 도입했습니다.IBM의 번호 체계 기원은 가장 작은(처음) 번호가 IBM의 EBCDIC 인코딩 변형에 할당되고 약간 큰 숫자는 PC 하드웨어에서 사용되는 IBM의 확장 ASCII 인코딩 변형에 해당한다는 사실에 반영됩니다.
PC DOS 버전 3.3(및 거의 동일한 MS-DOS 3.3)의 출시와 함께 IBM은 코드 페이지 번호 부여 시스템을 일반 PC 사용자에게 도입했습니다. 코드 페이지 번호(및 "코드 페이지"라는 문구)는 OS의 모든 부분에서 사용되는 문자 인코딩을 체계적인 [10]방식으로 설정할 수 있도록 새로운 명령에서 사용되었기 때문입니다.

1990년대 IBM과 마이크로소프트가 협력 관계를 끊은 후, 두 회사는 할당된 코드 페이지 번호 목록을 서로 독립적으로 유지해왔으며, 이로 인해 몇 가지 상반된 할당이 있었다.적어도 1개의 서드파티 벤더(Oracle)에는 독자적인 수치 [3]할당 리스트가 있습니다.반면 마이크로 소프트의 임무는 MSDN.[11]Additionally, 안에 어떤 주어진 윈도우 머신에 설치된 코드 페이지에 이름과 정확하게 InternetAssignedNumbersAuthority(인터넷 할당 번호 지정 위원회)약어의 목록을 레지스트리에서 그 기계(이 정보가에서 찾을 수 있어 문서화된 IBM의 현재 과제들 그들의 CCSID 저장소에 나열됩니다.rmaInternet Explorer 등의 Microsoft 프로그램에서 사용됩니다.
CJK 언어 및 베트남어를 제외한 대부분의 유명한 코드 페이지는 모든 코드 포인트를 8비트로 맞추고 각 코드 포인트를 하나의 문자로 매핑하는 것 이상을 수반하지 않습니다.또, 문자나 복잡한 스크립트등의 기술도 관여하지 않습니다.
표준(VGA 대응) PC 그래픽스 하드웨어의 텍스트 모드는 8비트 코드 페이지를 중심으로 구축되어 있습니다.다만, 2개의 코드를 동시에 사용할 수 있기 때문에, 어느 정도의 색심도가 저하해, 디스플레이 어댑터에 최대 8개까지 격납할 수 있기 때문에,[12] 간단하게 전환할 수 있습니다.이러한 하드웨어에 로드할 수 있는 서드파티 코드 페이지 글꼴이 선택되었습니다.그러나 현재는 운영체제 벤더가 그래픽 모드로 동작하는 독자적인 문자 인코딩 및 렌더링 시스템을 제공하고 이러한 하드웨어 제한을 완전히 회피하는 것이 일반적입니다.그러나 코드 페이지 번호로 문자 인코딩을 참조하는 시스템은 이메일 및 웹 페이지와 같은 다양한 프로토콜에서 사용하기 위해 IETF 및 IANA에 의해 지정된 문자열 식별자에 대한 효율적인 대안으로서 여전히 적용할 수 있다.
ASC와의 관계II
현재 사용되는 코드 페이지의 대부분은 128개의 제어 코드와 인쇄 가능한 문자를 나타내는 7비트 코드인 ASCII의 슈퍼셋입니다.과거에는 ASCII 코드의 8비트 구현이 최상위 비트를 0으로 설정하거나 네트워크 데이터 전송에서 패리티 비트로 사용했습니다.문자 데이터를 나타내기 위해 상위 비트를 사용할 수 있게 되었을 때, 총 256개의 문자와 제어 코드를 나타낼 수 있었습니다.IBM을 포함한 대부분의 공급업체는 텍스트 전용 출력 장치에서 원시 그래픽을 모방할 수 있는 다양한 언어 및 그래픽 요소에 사용되는 문자를 인코딩하기 위해 이 확장된 범위를 사용했습니다.이러한 "확장 ASCII 문자 집합"에 대한 공식적인 표준은 존재하지 않았으며 IBM이 EBCDIC 인코딩의 변형에 대해 항상 그래왔듯이, 공급업체들은 이 변형들을 코드 페이지라고 불렀다.
유니코드와의 관계
Unicode는 현재 및 역사적으로 사용된 모든 인간 언어의 모든 문자를 단일 문자 열거(실효적으로 하나의 큰 코드 페이지)에 포함시키기 위한 노력으로, 디지털로 저장된 텍스트를 처리할 때 서로 다른 코드 페이지를 구분할 필요가 없습니다.Unicode는 설계 프로세스에서 일부 코드 페이지를 1:1로 복사하여 많은 레거시 코드 페이지와의 하위 호환성을 유지하려고 합니다.Unicode의 명시적인 설계 목표는 모든 일반적인 레거시 코드 페이지 간에 왕복 변환을 허용하는 것이었지만, 이 목표는 항상 달성된 것은 아닙니다.일부 벤더(IBM 및 Microsoft 등)는 Unicode 인코딩에 시대착오적으로 코드 페이지 번호를 할당하고 있습니다.이 규약을 통해 코드 페이지 번호를 메타데이터로 사용하여 바이너리 저장 데이터가 발견되었을 때 올바른 디코딩 알고리즘을 식별할 수 있습니다.
IBM 코드 페이지
EBCDIC 기반 코드 페이지
이러한 코드 페이지는 IBM이 메인프레임 [13]컴퓨터용 EBCDIC 문자 집합에서 사용합니다.
- 1 – USA WP, 오리지널
- 2 – 미국
- 3 – USA 어카운팅 버전A
- 4 – 미국
- 5 – 미국
- 6 – 중남미
- 7 – 독일 F.R. / 오스트리아
- 8 – 독일 F.R.
- 9 – 프랑스, 벨기에
- 10 – 캐나다 (영어)
- 11 – 캐나다(프랑스어)
- 12 – 이탈리아
- 13 – 네덜란드
- 14 –
- 15 – 스위스(프랑스어)
- 16 – 스위스 (프랑스어/독일어)
- 17 – 스위스(독일)
- 18 – 스웨덴 / 핀란드
- 19 – 스웨덴 / 핀란드 WP, 버전 2
- 20 – 덴마크/노르웨이
- 21 – 브라질
- 22 – 포르투갈
- 23 – 영국
- 24 – 영국
- 25 – 일본 (라틴어)
- 26 – 일본 (라틴어)
- 27 – 그리스 (라틴어)
- 28 –
- 29 – 아이슬란드
- 30 – 터키
- 31 – 남아프리카 공화국
- 32 – 체코슬로바키아(체코/슬로바키아)
- 33 – 체코슬로바키아
- 34 – 체코슬로바키아
- 35 – 루마니아
- 36 – 루마니아
- 37 – 미국/캐나다 - CECP (유로와 동일: 1140)
- 37-2: C/370에서 사용되는 실제 3279 APL 코드 페이지.이는 캐럿과 부호 반전 이외의 경우는 1047에 매우 가깝습니다.SHARE가 이 [14]제품의 존재를 지적했음에도 불구하고 IBM은 이를 공식적으로 인정하지 않습니다.
- 38 – 미국 ASCII
- 39 – 영국 / 이스라엘
- 40 – 영국
- 251 – 중국
- 252 – 폴란드
- 254 – 헝가리
- 256 – 인터내셔널 넘버원 (500으로 대체)
- 257 – 인터내셔널 넘버2
- 258 – 인터내셔널 넘버3
- 259 – 기호, 세트 7
- 260 – 캐나다 프랑스어 - 116
- 264 – 프린트 트레인 및 텍스트 처리 연장
- 273 – 독일 F.R./오스트리아 - CECP (유로와 동일: 1141 )
- 274 – 구 벨기에 코드 페이지
- 275 – 브라질 - CECP
- 276 – 캐나다 (프랑스) - 94
- 277 – 덴마크, 노르웨이 - CECP (유로와 동일: 1142 )
- 278 – 핀란드, 스웨덴 - CECP (유로와 동일: 1143 )
- 279 – 프랑스어 - 94[14]
- 280 – 이탈리아 - CECP (유로와 동일: 1144)
- 281 – 일본 (라틴어) - CECP
- 282 – 포르투갈 - CECP
- 283 – 스페인 - 190[14]
- 284 – 스페인/라틴아메리카 - CECP (유로와 동일: 1145)
- 285 – 영국 - CECP (유로와 동일: 1146)
- 286 – 오스트리아 / 독일 F.R.교대하는
- 287 – 덴마크/노르웨이 대체
- 288 – 핀란드/스웨덴 대체
- 289 – 스페인 대체 서비스
- 290 – 일본어(카타카나) 확장
- 293 – APL
- 297 – 프랑스 (유로와 동일: 1147)[14]
- 298 – 일본 (카타카나)
- 300 – 일본 (한자) DBCS (JIS X 0213용)
- 310 – 그래픽 이스케이프 APL/TN
- 320 – 헝가리
- 321 – 유고슬라비아
- 322 – 터키
- 330 – 인터내셔널 넘버4
- 351 – GDM 디폴트
- 352 – 인쇄 및 출판 옵션
- 353 – BCDIC-A
- 355 – PTTC/BCD 표준 옵션
- 357 – PTTC/BCD H 옵션
- 358 – PTTC/BCD 대응 옵션
- 359 – PTTC/BCD 모노케이스 옵션
- 360 – PTTC/BCD Duocase 옵션
- 361 – EBCDIC Publishing International
- 363 – 기호, 세트 8
- 382 – EBCDIC 출판 오스트리아, 독일 F.R.교대하는
- 383 – EBCDIC 출판 벨기에
- 384 – EBCDIC 출판 브라질
- 385 – EBCDIC 출판 캐나다 (프랑스어)
- 386 – EBCDIC 출판 덴마크, 노르웨이
- 387 – EBCDIC 출판 핀란드, 스웨덴
- 388 – EBCDIC 출판 프랑스
- 389 – EBCDIC 출판 이탈리아
- 390 – EBCDIC 출판 일본 (라틴어)
- 391 – EBCDIC 출판 포르투갈
- 392 – EBCDIC 출판 스페인, 필리핀
- 393 – EBCDIC 출판 중남미 (스페인어)
- 394 – EBCDIC 출판 중국(홍콩), 영국, 아일랜드
- 395 – EBCDIC 출판 호주, 뉴질랜드, 미국, 캐나다 (영어)
- 410 – 키릴 문자(개정: 880, 1025, 1154)
- 420 – 아랍어
- 421 – 마그레브/프랑스어
- 423 – 그리스어(875로 대체)
- 424 – 히브리어(불레틴 코드)
- 425 – OS/390 Open Edition용 아랍어/라틴어
- 435 – 텔레텍스트 동형
- 500 – International #5 (ECECP, 256 대체) (유로: 1148과 동일)
- 803 – 히브리어 문자 집합 A(구 코드)
- 829 – 호스트 산술 기호 - 출판
- 833 – 한국어 확장 (SBCS)
- 834 – 한글 (KSC5601, DBCS with UDC)
- 835 – 중국어 번체 DBCS
- 836 – 중국어 간체 확장
- 837 – 중국어 간체 DBCS
- 838 – 태국어, 저점 및 악센트 문자 (유로와 동일: 1160)
- 839 – 태국 DBCS
- 870 – 라틴어 2 (유로화: 1153과 동일) (개정: 1110)
- 871 – 아이슬란드 (유로화: 1149와 [14]동일)
- 875 – 그리스어(대체 423)
- 880 – 키릴 문자 (개정판 410) (개정판: 1025, 1154 )
- 881 – 미국 - 5080 그래픽스 시스템
- 882 – 영국 - 5080 그래픽스 시스템
- 883 – 스웨덴 - 5080 그래픽스 시스템
- 884 – 독일 - 5080 그래픽스 시스템
- 885 – 프랑스 - 5080 그래픽스 시스템
- 886 – 이탈리아 - 5080 그래픽스 시스템
- 887 – 일본 - 5080 그래픽스 시스템
- 888 – 프랑스 AZERTY - 5080 그래픽스 시스템
- 889 – 태국
- 890 – 유고슬라비아
- 892 – EBCDIC, OCR A
- 893 – EBCDIC, OCR B
- 905 – 라틴어 3
- 918 – 우르두어 2개 국어
- 924 – 라틴어 9
- 930 – Japan MIX (290 + 300) (유로와 동일: 1390)
- 931 – Japan MIX (37 + 300)
- 933 – Korea MIX (833 + 834) (유로와 동일: 1364)
- 935 – 중국어 간체 MIX (836 + 837) (유로와 동일: 1388 )
- 937 – 중국어 번체 MIX (37 + 835) (유로와 동일: 1371 )
- 939 – Japan MIX (1027 + 300) (유로와 동일: 1399)
- 1001 – MICR
- 1002 – EBCDIC DCF Release 2 호환성
- 1003 – EBCDIC DCF, US 텍스트 서브셋
- 1005 – EBCDIC 동형 텍스트 통신
- 1007 – EBCDIC 아랍어 (XCOM2)
- 1024 – EBCDIC T.61
- 1025 – 키릴어, 다국어(유로와 동일: 1154)(개정판 880)
- 1026 – EBCDIC 터키(라틴어 5)(유로와 동일: 1155)(그 나라에서는 905로 대체)
- 1027 – 일본어(라틴어) 확장(JIS X 0201 확장)
- 1028 – EBCDIC 출판 히브리어
- 1030 – 일본어(카타카나) 확장
- 1031 – 일본어(라틴어) 확장
- 1032 – MICR, E13-B 조합
- 1033 – MICR, CMC-7 조합
- 1037 – 한국 - 5080/6090 그래픽스 시스템
- 1039 – GML 호환성
- 1047 – 라틴어 1/오픈[14] 시스템
- 1068 – DCF 호환성
- 1069 – 라틴어 4
- 1070 – 미국/캐나다 버전 0 (코드 페이지 37 버전 0)
- 1071 – 독일 F.R. / 오스트리아
- 1073 – 브라질
- 1074 – 덴마크, 노르웨이
- 1075 – 핀란드, 스웨덴
- 1076 – 이탈리아
- 1077 – 일본 (라틴어)
- 1078 – 포르투갈
- 1079 – 스페인 / 중남미 버전0 (코드 페이지 284 버전0)
- 1080 – 영국
- 1081 – 프랑스 버전 0 (코드 페이지 297 버전 0)
- 1082 – 이스라엘 (헤브루)
- 1083 – 이스라엘 (헤브루)
- 1084 – International #5 Version 0 (코드 페이지 500 Version 0)
- 1085 – 아이슬란드
- 1087 – 기호 세트
- 1091 – 기호 수정, 세트 7
- 1093 – IBM[15] 로고
- 1097 – Farsi 이중언어
- 1110 – 라틴어 2 (870 개정)
- 1112 – 발틱 다국어 (유로와 동일: 1156)
- 1113 – 라틴어 6
- 1122 – 에스토니아 (유로와 동일: 1157)
- 1123 – 우크라이나 키릴 문자(유로와 동일: 1158)
- 1130 – 베트남어 (유로와 동일: 1164)
- 1132 – Lao EBCDIC
- 1136 – 히타치 가타카나
- 1137 – 데바나가리 EBCDIC
- 1140 – 미국, 캐나다 등 ECECP (유로화 제외 동일: 37) (번체 중국어 버전: 1159 )
- 1141 – 오스트리아, 독일 ECECP (유로화 제외 동일: 273)
- 1142 – 덴마크, 노르웨이 ECECP (유로화 제외 동일: 277)
- 1143 – 핀란드, 스웨덴 ECECP (유로화 제외 동일: 278)
- 1144 – 이탈리아 ECECP (유로 제외시 동일: 280)
- 1145 – 스페인, 중남미(스페인어) ECECP (유로화 제외 동일: 284)
- 1146 – 영국 ECECP (유로화 제외 동일: 285)
- 1147 – 프랑스 ECECP(유로화 포함) (유로화 제외 시 동일: 297)
- 1148 – International ECECP(유로화 포함) (유로화 제외 시 동일: 500)
- 1149 – 아이슬란드 ECECP(유로 포함) (유로 제외 시 동일: 871)
- 1150 – 한국어 확장자(상자 포함)
- 1151 – 중국어 간체 확장자(상자 포함)
- 1152 – 중국어 번체 확장자(상자 포함)
- 1153 – 라틴어 2 (유로화 포함) (유로화 제외시 동일: 870)
- 1154 – 키릴어, 유로화 포함 다국어(유로화 제외 동일: 1025, 이전 버전은 * 1166)
- 1155 – 터키 (유로화 없음 동일: 1026)
- 1156 – 발틱 멀티(유로화 포함) (유로화 제외 시 동일: 1112)
- 1157 – 에스토니아(유로화 포함) (유로화 제외 시 동일: 1122)
- 1158 – 우크라이나 키릴 문자(유로화 포함) (유로화 제외 시 동일:1123)
- 1159 – T-Chinese EBCDIC (중국어 번체 유로화 업데이트* 1140)
- 1160 – 태국어 (저점 & 악센트 문자, 유로화 포함) (유로화 제외 시 동일: 838)
- 1164 – 베트남어(유로화 포함) (유로화 제외 시 동일: 1130)
- 1165 – 라틴어 2/오픈 시스템
- 1166 – 키릴 카자흐스탄어
- 1278 – EBCDIC Adobe (PostScript) 표준 부호화
- 1279 – 히타치 일본어 가타카나[6] 호스트
- 1303 – EBCDIC 바코드
- 1364 – Korea MIX (833 + 834 + 유로) (유로 제외 동일: 933)
- 1371 – 중국어 번체 MIX(1159 + 835) (유로화 제외 동일: 937)
- 1376 – HKSCS용 중국어 번체 DBCS 호스트 확장
- 1377 – 혼합 호스트 HKSCS 증가 (37 + 1376)
- 1388 – 중국어 간체 MIX (유로화 제외 동일: 935) (836 + 837 + 유로)
- 1390 – 간체 중국어 MIX Japan MIX (유로 제외 동일: 930) (290 + 300 + 유로)
- 1399년 – 일본 MIX(1027년+300+유로)(유로 없이:939년 같은).
DOS 코드 페이지
이 코드 페이지 IBM에 의해 그것의 PC도스 운영 체제에 사용된다.이 코드 페이지는 원래 직접적으로 그래픽 어댑터는 IBMPC와 그 복제에 사용되는 원본 MDA과 이화 물질 유전자 활성제 어댑터의 문자 집합만 신체적으로 글꼴이 들어 있는 ROM칩 교체를 통해 바꿀 수 있는 등 텍스트 모드 하드웨어에 박혀 있었다.(VGA와 같은 모든 후기 어댑터들이 경쟁)는 일반적으로 각 font/encoding(비록 VGA가 약간 큰 문자 집합에 대해 부분적으로 지원이라고 덧붙였다)에 256캐릭터로 싱글 바이트 문자 집합으로 제한되었습니다 그 어댑터의 인터페이스.
- 301 – IBM-PC Japan (한자) DBCS
- 437 – 원본 IBM PC 하드웨어 코드 페이지
- 720 – 아랍어 (투명 ASMO)
- 737 – 그리스어
- 775 – Latin-7
- 808 – 러시아어(유로화 포함) (유로화 제외 시 동일: 866)
- 848 – 우크라이나어(유로화 포함) (유로화 제외 시 동일: 1125)
- 849 – 벨로루시(유로 포함) (유로 제외 시 동일: 1131)
- 850 – Latin-1
- 851 – 그리스어
- 852 – Latin-2
- 853 – Latin
- 855 – 키릴 문자(유로와 동일: 872)
- 856 – 히브리어
- 857 – Latin-5
- 858 – 라틴어 1 (유로 기호 포함)
- 859 – Latin-9
- 860 – 포르투갈어
- 861 – 아이슬란드어
- 862 – 히브리어
- 863 – 캐나다 프랑스어
- 864 – 아랍어
- 865 – 덴마크어/노르웨이어
- 866 – 벨라루스어, 러시아어, 우크라이나어(유로와 동일: 808)
- 867 – 히브리어 + 유로(CP862 기준) (컨플릭트 ID: NEC 체코어(Kamenick),), 본 코드 페이지 이전에 작성)
- 868 – 우르두
- 869 – 그리스어
- 872 – 키릴 문자(유로화 포함) (유로화 제외 시 동일: 855)
- 874 – 낮은 톤 마크와 고대 문자를 사용하는 태국어(Windows 874와 경합하는 ID, 유로 버전: 1161 Windows 버전: IBM 1162)
- 876 – OCR A
- 877 – OCR B
- 878 – KOI8-R
- 891년– 한국 PCSBCS
- 898– IBM-PC WP다중 언어
- 899년 – IBM-PC 기호
- 903년 – 중국어 간체 PCSBCS.
- 904년 – 중국어 번체 PCSBCS.
- 906년 – 국제 설정#53812/3820.
- 907– 아스키 에이피엘 프로그래밍 언어(3812)
- 909년 – IBM-PC APL2 확장
- 910– IBM-PC APL2
- 911– IBM-PC 일본#1
- 926년– 한국 PC더블 바이트 문자 집합
- 927년 – 중국어 번체 PC더블 바이트 문자 집합.
- 928년 – 중국어 간체 PC더블 바이트 문자 집합.
- 929– 태국 PC더블 바이트 문자 집합
- 932– IBM-PC 일본 MIX(더블 바이트 문자 집합)(897년+301)(Windows932로 대립하는 ID;Windows버전은 IBM943)(DOS/V).
- 934년 – IBM-PC 한국 MIX(DOS/V)(더블 바이트 문자 집합)(891년+926년).
- 936 – IBM-PC 중국어 간체 MIX (gb2312) (DOS/V) (DBCS) (903 + 928) (Windows 936과의 충돌 ID, Windows 버전은 IBM 1386)
- 938 – IBM-PC 번체 중국어 믹스(DOS/V, OS/2) (904 + 927
- 942 – IBM-PC Japan MIX (일본어 SAA (OS/2)) (1041 + 301)
- 943 – IBM-PC Japan OPEN (897 + 941) (Windows CP 932 )
- 944 – IBM-PC Korea MIX (한국어판 SAA (OS/2)) (1040 + 926)
- 946 – IBM-PC 중국어 간체(간체 중국어 SAA(OS/2)) (1042 + 928)
- 948 – IBM-PC 번체 중국어(번체 중국어 SAA(OS/2)) (1043 + 927)
- 949 – 한국어 (확장 Wansung (ks_c_5601-1987)) (1088 + 951) (Windows 949 (통합 한글 코드), Windows 버전은 IBM 1363)
- 951 – 한국어 DBCS (IBM KS 코드) (Windows 951과의 컨플릭트 ID, HKSCS에서 발견된 일부 PUA Unicode 문자에 대한 Unicode 매핑이 포함된 Windows 950의 해킹, 파일명에 근거함)
- 1034 – 프린터 어플리케이션 - 배송 라벨, 세트 #2
- 1040 – 한국어 확장판
- 1041 – 일본어 확장 (JIS X 0201 확장)
- 1042 – 중국어 간체 확장판
- 1043 – 중국어 번체 확장
- 1044 – 프린터 어플리케이션 - 배송 라벨, 세트 #1
- 1086 – IBM-PC Japan #1
- 1088 – 개정판 한국어 (SBCS)
- 1092 – IBM-PC 수정 기호
- 1098 – Farsi
- 1108 – DITROFF 기본 호환성
- 1109 – DITROFF 스페셜 호환성
- 1115 – IBM-PC 중화인민공화국
- 1116 – 에스토니아어
- 1117 – 라트비아어
- 1118 – 리투아니아어 (IBM의 Lika 코드 페이지 774 구현)
- 1119 – 리투아니아어 및 러시아어 (IBM의 Lika 코드 페이지 772 구현)
- 1125 – 키릴어, 우크라이나어(유로어: 848과 동일)(RUSCII의 IBM 변조)
- 1127 – IBM-PC 아랍어 / 프랑스어
- 1131 – IBM-PC Data, 키릴 문자, 벨라루스어(유로: 849와 동일)
- 1139 – 일본 영숫자 가타카나
- 1161 – 낮은 톤의 태국어 & 고대 문자(유로화 포함 포함) (유로화
- 1167 – KOI8-RU
- 1168 – KOI8-U
- 1300 – ANSI [PTS-DOS 6.70, 6.51 아님]
- 1370 – 중국어 번체 MIX (Big5 인코딩) (1114 + 947 + 유로) (유로화 제외 동일: 950)
- 1380 – IBM-PC 중국어 간체 GB PC-DATA (DBCS PC IBM GB 2312-80)
- 1381 – IBM-PC 간체 중국어 (1115 + 1380)
- 1393 – 일본어 JIS X 0213 DBCS
- 1394 – IBM-PC Japan (JIS X 0213) (897 + 1393)
오래된 하드웨어, 프로토콜 및 파일 형식을 다룰 때 이러한 코드 페이지를 지원해야 하는 경우가 많지만 새로운 설계에는 새로운 인코딩 시스템, 특히 유니코드를 권장합니다.
DOS 코드 페이지는 보통 에 저장됩니다.CPI [16][17][18][19][20]파일
IBM AIX 코드 페이지
이러한 코드 페이지는 IBM이 AIX 운영 체제에서 사용합니다.이들은 UNIX와 유사한 운영 체제와 같이 ISO에 따라 사용하도록 설계된 여러 문자 집합을 에뮬레이트합니다.
- 367 – 7비트 US-ASCII
- 371 – 7 비트 US-ASCII APL
- 806 – ISCII
- 813 – ISO 8859-7
- 819 – ISO 8859-1
- 895 – 7비트 일본 라틴어
- 896 – 7비트 일본 가타카나 확장
- 901 – ISO 8859-13(유로화 포함)의 확장(유로화 없음: 921)
- 902 – ISO 에스토니아어(유로화 포함) (유로화 제외 시 동일: 922)
- 912 – ISO 8859-2 확장
- 913 – ISO 8859-3
- 914 – ISO 8859-4
- 915 – ISO 8859-5 확장
- 916 – ISO 8859-8
- 919 – ISO 8859-10
- 920 – ISO 8859-9
- 921 – ISO 8859-13의 확장(유로: 901)
- 922 – ISO 에스토니아어(유로: 902와 동일)
- 923 – ISO 8859-15
- 952 – JIS X 0208의 EUC 일본어
- 953 – EUC 일본어 (JIS X 0212 용)
- 954 – EUC 일본어 (895 + 952 + 896 + 953)
- 955 – TCP 일본어, JIS X 0208-1978
- 956 – TCP 일본어 (895 + 952 + 896 + 953)
- 957 – TCP 일본어 (895 + 955 + 896 + 953)
- 958 – TCP 일본어 (367 + 952 + 896 + 953)
- 959 – TCP 일본어 (367 + 955 + 896 + 953)
- 960 – 중국어 번체 DBCS-EUC SICGCC 프라이머리 세트 (첫 번째 플레인)
- 961 – 중국어 번체 DBCS-EUC SICGCC 풀세트 + IBM Select + UDC
- 963 – 중국어 번체 TCP, CNS 11643 플레인2 만
- 964 – EUC 번체 중국어 (367 + 960 + 961)
- 965 – TCP 번체 중국어 (367 + 960 + 963)
- 970 – EUC 한국어 (367 + 971)
- 971 – EUC Korean DBCS (G1, KSC 5601 1989 (188 UDC 포함))
- 1006 – ISO 8비트 Urdu
- 1008 – ISO 8비트 아랍어
- 1009 – 7비트 ISO IRV
- 1010 – 7비트 프랑스
- 1011 – 7비트 독일 F.R.
- 1012 – 7비트 이탈리아
- 1013 – 7비트 영국
- 1014 – 7비트 스페인
- 1015 – 7 비트 포르투갈
- 1016 – 7비트 노르웨이
- 1017 – 7비트 덴마크
- 1018 – 7비트 핀란드/스웨덴
- 1019 – 7비트 네덜란드
- 1029 – 아랍어 확장
- 1036 – CCITT T.61
- 1046 – 아랍어 확장 (유로)
- 1089 – ISO 8859-6
- 1111 – ISO 8859-2
- 1124 – ISO 우크라이나어, ISO 8859-5와 유사
- 1129 – ISO 베트남어 (유로화: 1163과 동일)
- 1133 – ISO 라오스
- 1163 – ISO 베트남어(유로화 포함) (유로화 제외 시 동일:1129)
- 1350 – EUC 일본어 (JISeucJP) (367 + 952 + 896 + 953)
- 1382 – EUC 간체 중국어 (DBCS PC GB 2312-80)
- 1383 – EUC 간체 중국어 (367 + 1382)
코드 페이지 819는 라틴어-1, ISO/IEC 8859-1과 동일하며 약간 변경된 명령어를 사용하면 MS-DOS 머신이 이 인코딩을 사용할 수 있습니다.IBM AS/400 미니컴퓨터와 함께 사용되었습니다.
IBM OS/2 코드 페이지
이러한 코드 페이지는 IBM이 OS/2 운영 체제에서 사용합니다.
Windows 에뮬레이션코드 페이지
이러한 코드 페이지는, IBM 가 Microsoft Windows 문자 세트를 에뮬레이트 할 때에 사용합니다.이러한 코드 페이지의 대부분은, Microsoft 코드 페이지와 같은 번호이지만, 완전히 동일하지는 않습니다.그러나 일부 코드 페이지는 마이크로소프트가 고안하지 않은 IBM의 새로운 페이지입니다.
- 897 – IBM-PC SBCS 일본어 (JIS X 0201-1976)
- 941 – IBM-PC 일본어 DBCS for Open Environment
- 947 – IBM-PC DBCS for (Big5 인코딩)
- 950 – 중국어 번체 MIX (Big5 인코딩) (1114 + 947) (유로와 동일: 1370)
- 1114 – IBM-PC SBCS (간체 중국어, GBK, 번체 중국어, Big5 인코딩)
- 1126 – IBM-PC 한국어 SBCS
- 1162 – Windows 태국어(확장 874. 단, Windows에서는 계속 그렇게 불리고 있습니다.
- 1169 – Windows 키릴 문자 아시아어
- 1174 – Windows[22] 카자흐스탄어
- 1250 – Windows 중앙 유럽
- 1251 – Windows 키릴 문자
- 1252 – Windows Western
- 1253 – Windows 그리스어
- 1254 – Windows 터키어
- 1255 – Windows 히브리어
- 1256 – Windows 아랍어
- 1257 – Windows Baltic
- 1258 – Windows 베트남어
- 1361 – 한국어(JOHAB)
- 1362 – 한글 DBCS
- 1363 – Windows 한국어(1126 + 1362) (Windows CP 949)
- 1372 – IBM-PC MS T Chinese Big5 인코딩 (DB2 전용)
- 1373 – Windows 번체 중국어 (확장 950)
- 1374 – IBM-PC DB Big5 HKSCS 인코딩 확장
- 1375 – HKSCS용 Big5 부호화 확장 혼재(950과 일치)
- 1385 – IBM-PC 중국어 간체 DBCS (GB18030용 CS 성장, GBK PC-DATA에도 사용)
- 1386 – IBM-PC 중국어 간체 GBK (1114 + 1385) (Windows CP 936)
- 1391 – 중국어 간체 4바이트 (GB18030용 CS 증가, GBK PC-DATA에도 사용)
- 1392 – IBM-PC 간체 중국어 믹스(1252 + 1385 + 1391)
Macintosh 에뮬레이션코드 페이지
이러한 코드 페이지는 IBM이 Apple Macintosh 문자 집합을 에뮬레이트할 때 사용합니다.
Adobe 에뮬레이션코드 페이지
이러한 코드 페이지는 IBM이 Adobe 문자 집합을 에뮬레이트할 때 사용합니다.
HP 에뮬레이션코드 페이지
이러한 코드 페이지는 IBM이 HP 문자 집합을 에뮬레이트할 때 사용합니다.
DEC 에뮬레이션코드 페이지
이러한 코드 페이지는, DEC 문자 세트를 에뮬레이트 할 때에 IBM 에 의해서 사용됩니다.
- 1020 – 7비트 캐나다(프랑스) NRC 세트
- 1021 – 7비트 스위스 NRC 세트
- 1023 – 7비트 스페인어 NRC 세트
- 1090 – 특수 문자 및 선 그리기 세트
- 1100 – DEC 다국어
- 1101 – 7비트 영국 NRC 세트
- 1102 – 7비트 네덜란드 NRC 세트
- 1103 – 7비트 핀란드 NRC 세트
- 1104 – 7비트 프랑스 NRC 세트
- 1105 – 7비트 노르웨이/덴마크 NRC 세트
- 1106 – 7비트 스웨덴 NRC 세트
- 1107 – 7비트 노르웨이/덴마크 NRC 대체
- 1287 – DEC 그리스어
- 1288 – 12월 터키어
IBM Unicode 코드 페이지
- 1200 – UTF-16BE Unicode(빅엔디안) 및 IBM PUA([23]개인 사용 영역)
- 1201 – UTF-16BE Unicode (빅엔디안)[23]
- 1202 – UTF-16LE Unicode(리틀 엔디안) 및 IBM[23] PUA
- 1203 – UTF-16LE Unicode (리틀엔디안)[23]
- 1208 – UTF-8 Unicode with IBM PUA[23]
- 1209 – UTF-8 Unicode[23]
- 1400 – ISO 10646 UCS-BMP (Unicode 6.0 [23]기반)
- 1401 – ISO 10646 UCS-SMP (Unicode 6.0 [23]기반)
- 1402 – ISO 10646 UCS-SIP (Unicode 6.0 [23]기반)
- 1414 – ISO 10646 UCS-SSP (Unicode 4.0 [23]기반)
- 1445 – IBM AFP PUA No.1
- 1446 – ISO 10646 UCS-PUP15 (Unicode 4.0 [23]기반)
- 1447 – ISO 10646 UCS-PUP16 (Unicode 4.0 [23]기반)
- 1448 – UCS-BMP(일반 UDC)
- 1449 – IBM 기본 PUA
Microsoft 코드 페이지
Windows 코드 페이지
이러한 코드 페이지는, Microsoft 가 독자적인 Windows operating system으로 사용하고 있습니다.Microsoft는 ANSI 코드 페이지로 알려진 다수의 코드 페이지를 정의했습니다(첫 번째 코드 페이지로서 1252는 ISO 8859-1이 된 ANSI 초안에 근거하고 있습니다).코드 페이지 1252는 ISO 8859-1을 기반으로 구축되어 있지만 ISO 8859-1에서 [24]언급된 ISO 6429의 C1 제어 코드가 아닌 0x80-0x9F 범위를 인쇄 가능한 추가 문자로 사용합니다.그 외 일부는 ISO 8859의 다른 부분에 기초하고 있지만, 종종 1252에 가깝게 재배치됩니다.
Microsoft 에서는, 이러한 코드 [25]페이지 대신에 UTF-8 또는 UCS-2/UTF-16 를 사용하는 것을 추천합니다.
DBCS 코드 페이지
이 코드 페이지는 다양한 CJK 언어의 DBCS 문자 인코딩을 나타냅니다.Microsoft operating system에서는, 이것들은 해당하는 로케일의 「OEM」코드 페이지와 「Windows」코드 페이지로서 모두 사용됩니다.
MS-DOS 코드 페이지
이러한 코드 페이지는, Microsoft 의 MS-DOS operating system에서 사용되고 있습니다.Microsoft에서는 OEM 코드 페이지라고 부릅니다.이는 MS-DOS를 하드웨어와 함께 배포하기 위해 라이선스를 취득한 원기기의 제조원에 의해 정의되었기 때문입니다.Microsoft나 표준 조직에 의해 정의되는 것은 아닙니다.이러한 코드 페이지의 대부분은 동일한 IBM 코드 페이지와 동일한 번호를 가지고 있지만, 완전히 동일하지는 않습니다.일부 코드 페이지에는 IBM 및 Microsoft와 최소한의 차이가[26] 있습니다.
- 708 – 아랍어(ASMO 708)
- 709 – 아랍어(ASMO 449+/BCON V4)
- 710 – 아랍어 (투명 아랍어)
- 720 – 아랍어 (투명 ASMO)
- 737 – 그리스어
- 850 – Latin-1
- 851 – 그리스어
- 852 – Latin-2
- 855 – 키릴 문자
- 857 – Latin-5
- 858 – 라틴어 1 (유로 기호 포함)
- 859 – Latin-9
- 860 – 포르투갈어
- 861 – 아이슬란드어
- 862 – 히브리어
- 863 – 캐나다 프랑스어
- 864 – 아랍어
- 865 – 덴마크어/노르웨이어
- 866 – 벨라루스어, 러시아어, 우크라이나어
- 869 – 그리스어
Macintosh 에뮬레이션코드 페이지
이러한 코드 페이지는, Microsoft 가 Apple Macintosh 문자 세트를 에뮬레이트 할 때에 사용합니다.
- 10000 - Apple Macintosh 로마자
- 10001 - Apple 일본어
- 10002 - Apple 번체 중국어 (Big5)
- 10003 - 애플 한국어
- 10004 - 애플 아랍어
- 10005 - 애플 히브리어
- 10006 - 애플 그리스어
- 10007 - Apple Macintosh 키릴 문자
- 10008 - Apple 간체 중국어 (GB 2312)
- 10010 - Apple 루마니아어
- 10017 - 애플 우크라이나어
- 10021 - 애플타이
- 10029 - Apple Macintosh 중앙 유럽
- 10079 - 애플 아이슬란드어
- 10081 - 애플 터키어
- 10082 - 애플 크로아티아어
기타 다양한 Microsoft 코드 페이지
다음의 코드 페이지 번호는, Microsoft Windows 전용입니다.IBM은 이러한 코드 페이지에 다른 번호를 사용할 수 있습니다.이들은 UNIX와 유사한 운영 체제와 같이 [clarification needed]ISO에 따라 사용하도록 설계된 여러 문자 집합을 에뮬레이트합니다.
- 20000 – 중국어 번체 CNS
- 20001 – 중국어 번체 TCA
- 20002 – 중국어 번체 ETEN
- 20003 – 중국어 번체 IBM5500
- 20004 – 중국어 번체 텔레텍스트
- 20005 – 중국어 번체 Wang
- 20105 – 7비트 IA5 IRV[27][28][29] (CP 1009)
- 20106 – 7비트 IA5 독일어 (DIN 66003)[27][28][30]
- 20107 – 7비트 IA5 스웨덴어 (SEN 850200 C)[27][28][31]
- 20108 - 7비트 IA5 노르웨이어(NS 4551-2)[27][28][32]
- 20127 – 7비트 US-ASCII[27][28][33]
- 20261 – CCITT T.61
- 20269 – ISO 6937
- 20273
- 20277
- 20278
- 20284
- 20285
- 20290 - EBCD 일본어IC
- 20297
- 20420
- 20423
- 20424
- 20833
- 20838
- 20866 – KOI8-R
- 20871
- 20880 – EBCDIC 키릴 문자(880)
- 20905
- 20924
- 20932 - EUC-JP
- 20936
- 20949
- 21025 – EBCDIC 키릴 문자 (1025)
- 21027
- 21866 – KOI8-U
- 28591 – ISO-8859-1
- 28592 – ISO-8859-2
- 28593 – ISO-8859-3
- 28594 – ISO-8859-4
- 28595 – ISO-8859-5
- 28596 – ISO-8859-6
- 28597 – ISO-8859-7
- 28598 – ISO-8859-8
- 28599 – ISO-8859-9
- 28600 – ISO-8859-10
- 28601 – ISO-8859-11
- 28602 – 미사용 (ISO-8859-12용으로 예약)
- 28603 – ISO-8859-13
- 28604 – ISO-8859-14
- 28605 – ISO-8859-15
- 28606 – ISO-8859-16
- 38596 – ISO-8859-6
- 38598 – ISO-8859-8
Microsoft Unicode 코드 페이지
HP 심볼 세트
HP는 자체 문자 집합 또는 다른 벤더의 문자 집합을 인코딩하기 위해 일련의 기호 집합(각각 관련 기호 집합 코드 포함)을 개발했다.일반적으로 상위 부분으로 이동하여 ASCII 문자 집합과 관련지어지면 8비트 문자 집합을 구성하는 문자 집합은 8비트 문자 집합입니다.
HP 자체 기호 세트
- 기호 세트 0E - HP Roman Extension - 악센트 문자로 구성된 7비트 문자 세트 (코드 페이지 1050으로 IBM에 의해 코드화됨)
- 심볼 세트 0G - HP 7비트 독일어
- 기호 세트 0L - HP 선 그리기(코드 페이지 1056으로 IBM에 의해 코드화됨)
- 기호 세트 0M - HP Math-7
- 심볼 세트 0T - HP Tai-8
- 심볼 세트 1S - HP 7비트 스페인어
- 심볼 세트 1U - HP 7비트 Gothic Legal (코드 페이지 1052로 IBM에 의해 코드화됨)
- 심볼 세트 4Q - 7비트 PC 라인 (코드 페이지 1055로 IBM에 의해 코드화됨)
- 기호 세트 4U - HP Roman-9 - Roman-8 + €
- 심볼 세트 7J - HP 데스크톱
- 심볼 세트 7S - HP 7비트 유럽 스페인어
- 심볼 세트 8E - HP East-8
- 심볼 세트 8G - HP Greek-8 (IR 088 기반, ELOT 927 기반 아님)
- 기호 세트 8H - HP 히브리어-8
- 심볼 세트 8I - MS LineDraw (ASCII + HP PC 라인)
- 기호 세트 8K - HP Kana-8 (ASCII + 일본어 가타카나)
- 심볼 세트 8L - HP LineDraw (ASCII + HP LineDraw)
- 기호 세트 8M - HP Math-8 (ASCII + HP Math-8)
- 기호 세트 8R - HP Cyrillic-8
- 심볼 세트 8S - HP 7비트 중남미 스페인어
- 심볼 세트 8T - HP 터키어-8
- 기호 세트 8U - HP Roman-8 (ASCII + HP Roman Extension, 코드 페이지 1051로 IBM에 의해 코드화됨)
- 심볼 세트 8V - HP 아랍어-8
- 기호 세트 9K - HP 한국어-8
- 기호 세트 9T - PC 8T (코드 페이지 437-T라고도 합니다.코드 페이지 857은 아닙니다)
- 기호 세트 9V - Windows용 라틴어/아랍어 (코드 페이지 1256은 아닙니다)
- 심볼 세트 11U - PC 8D/N (코드 페이지 437-N이라고도 하며, 코드 페이지 1058로 IBM에 의해 코드화됨, 코드 페이지 865가 아님)
- 기호 세트 14G - PC-8 그리스어 대체(코드 페이지 437-G라고도 함, 코드 페이지 737과 거의 동일)
- 기호 세트 18K -
- 기호 세트 18T -
- 기호 세트 19C -
- 기호 세트 19K -
다른 벤더의 기호 세트
- 심볼 세트 0D - ISO 60: 7비트 노르웨이어
- 심볼 세트 0F - ISO 25: 7비트 프랑스어
- 기호 세트 0H - HP 7비트 히브리어 - 이스라엘 표준 SI 960과 거의 동일
- 심볼 세트 0I - ISO 15: 7비트 이탈리아어
- 기호 세트 0K - ISO 14: 7비트 일본어 가타카나
- 기호 집합 0N - ISO 8859-1 라틴어 1(처음에는 "Gothic-1"로 불림, 코드 페이지 1052로 IBM에 의해 코드화됨)
- 기호 세트 0R - ISO 8859-5 라틴어/키릴어 (1986 버전 - IR 111)
- 심볼 세트 0S - ISO 11: 7비트 스웨덴어
- 심볼 세트 0U - ISO 6: 7비트 미국
- 기호 세트 0V - 아랍어
- 심볼 세트 1D - ISO 61: 7비트 노르웨이어
- 심볼 세트 1E - ISO 4: 7비트 U.K.
- 심볼 세트 1F - ISO 69: 7비트 프랑스어
- 심볼 세트 1G - ISO 21: 7비트 독일어
- 기호 세트 1K - ISO 13: 7비트 일본어 라틴어
- 심볼 세트 1T - Windows Thai (874와 실질적으로 동일)
- 기호 세트 2K - ISO 57: 7비트 간체 중국어 라틴어
- 심볼 세트 2N - ISO 8859-2 라틴어 2
- 심볼 세트 2S - ISO 17:7 비트 스페인어
- 심볼 세트 2U - ISO 2: 7비트 국제 레퍼런스 버전
- 심볼 세트 3N - ISO 8859-3 라틴어 3
- 심볼 세트 3R - PC-866 러시아 (실제로는 코드 페이지 866과 동일)
- 심볼 세트 3S - ISO 10: 7비트 스웨덴어
- 기호 세트 4N - ISO 8859-4 라틴어 4
- 심볼 세트 4S - ISO 16:7 비트 포르투갈어
- 기호 세트 5M - PS 연산 기호 (실제로는 Adobe 기호와 동일)
- 심볼 세트 5N - ISO 8859-9 라틴어 5
- 심볼 세트 5S - ISO 84:7 비트 포르투갈어
- 심볼 세트 5T - Windows 3.1 Latin-5 (실제로는 코드 페이지 1254와 동일)
- 심볼 세트 6J - Microsoft 퍼블리싱
- 기호 세트 6M — Ventura 산술
- 심볼 세트 6N - ISO 8859-10 라틴어 6
- 심볼 세트 6S - ISO 85: 7비트 스페인어
- 기호 세트 7H - ISO 8859-8 라틴/헤브루
- 심볼 세트 9E - Windows 3.1 라틴어 2 (실제로는 코드 페이지 1250과 동일)
- 기호 세트 9G - Windows 98 그리스어 (실제로는 코드 페이지 1253과 동일)
- 심볼 세트 9J - PC 1004
- 기호 세트 9L - Ventura ITC Zapf Dingbats
- 기호 세트 9N - ISO 8859-15 라틴어 9
- 심볼 세트 9R - Windows 98 키릴 문자 (실제로는 코드 페이지 1251과 동일)
- 심볼 세트 9U - Windows 3.0
- 심볼 세트 10G - PC-851 라틴어/그리스어 (실제로는 코드 페이지 851과 동일)
- 심볼 세트 10J - PS 텍스트 (실제로 Adobe Standard와 동일)
- 심볼 세트 10L - PS ITC Zapf Dingbats (실제로 Adobe Dingbats와 동일)
- 심볼 세트 10N - ISO 8859-5 라틴어/키릴어 (1988 버전 - IR 144)
- 심볼 세트 10R - PC-855 키릴 문자 (실제로 코드 페이지 855와 동일)
- 심볼 세트 10T - Telectex
- 기호 세트 10U - PC-8 (실제로 코드 페이지 437과 동일, 코드 페이지 1057로 IBM에 의해 코드화됨)
- 심볼 세트 10V - CP-864 (코드 페이지 864와 실질적으로 동일)
- 심볼 세트 11G - CP-869 (실질적으로 코드 페이지 869와 동일)
- 심볼 세트 11J - PS ISO Latin-1 (Adobe Latin-1과 실질적으로 동일)
- 심볼 세트 11N - ISO 8859-6 라틴어/아랍어
- 기호 세트 12G - PC 라틴어/그리스어 (실제로는 코드 페이지 737과 동일)
- 심볼 세트 12J - MC 텍스트 (Macintosh Roman과 실질적으로 동일)
- 기호 세트 12N - ISO 8859-7 라틴어/그리스어
- 심볼 세트 12R - PC Gost (PC GOST Main과 실질적으로 동일)
- 심볼 세트 12U - PC-850 라틴어 1 (실제로는 코드 페이지 850과 동일)
- 기호 세트 13J - Ventura International
- 심볼 세트 13R - PC 불가리아어 (실질적으로 MIK와 동일)
- 기호 세트 13U - PC-858 라틴어 1 + € (실제로는 코드 페이지 858과 동일)
- 기호 세트 14J — 미국 Ventura.
- 기호 세트 14L - Windows Dingbats
- 기호 세트 14P - ABICOMP International (실질적으로 ABICOMP와 동일)
- 기호 세트 14R - PC 우크라이나어 (RUSCII와 실질적으로 동일)
- 기호 세트 15H - PC-862 이스라엘 (실질적으로 코드 페이지 862와 동일)
- 심볼 세트 16U - PC-857 Latin 5 (실제로는 코드 페이지 857과 동일)
- 심볼 세트 17U - PC-852 라틴어 2 (852 페이지와 실질적으로 동일)
- 심볼 세트 18N - UTF-8
- 심볼 세트 18U - PC-853 Latin 3 (실제로는 코드 페이지 853과 동일)
- 심볼 세트 19L - Windows 98 Baltic (실제로는 코드 페이지 1257과 동일)
- 기호 세트 19M - Windows 기호
- 심볼 세트 19U - Windows 3.1 라틴어 1 (실제로는 코드 페이지 1252와 동일)
- 심볼 세트 20U - PC-860 포르투갈 (실제로는 코드 페이지 860과 동일)
- 심볼 세트 21U - PC-861 아이슬란드 (실질적으로 코드 페이지 861과 동일)
- 심볼 세트 23U - PC-863 캐나다 - 프랑스어 (실제로 코드 페이지 863과 동일)
- 심볼 세트 24Q - PC-Polish Mazowia (실질적으로 Mazovia 인코딩과 동일)
- 심볼 세트 25U - PC-865 덴마크/노르웨이 (실질적으로 코드 페이지 865와 동일)
- 심볼 세트 26U - PC-775 라틴어 7 (실제로는 코드 페이지 775와 동일)
- 심볼 세트 27Q - PC-8 PC Nova (PC Nova와 실질적으로 동일)
- 심볼 세트 27U - PC 라트비아어 러시아어 (866-Latvian이라고도 함)
- 기호 세트 28U - PC 리투아니아어/러시아어(실질적으로 코드 페이지 774와 동일)
- 기호 세트 29U - PC-772 리투아니아어/러시아어 (실제로는 코드 페이지 772와 동일)
다른 벤더의 코드 페이지
이러한 코드 페이지는 서드파티 벤더의 독립된 할당입니다.원래의 IBM PC 코드 페이지(번호 437)는 실제로 국제적인 사용을 위해 설계되지 않았기 때문에, 부분적으로 호환되는 국가 또는 지역별 변종이 몇 가지 등장했습니다.
이러한 코드 페이지 번호 할당은 IBM이나 Microsoft에 의해서도 공식적이지 않으며 IANA에 의해 사용 가능한 문자 집합으로 참조되는 것은 거의 없습니다.이러한 코드 페이지에 할당된 번호는 임의이며 IBM 또는 Microsoft에서 사용 중인 등록된 번호와 충돌할 수 있습니다.그 중 일부는 DOS 3.3에서 코드 페이지 전환이 추가되기 전일 수 있습니다.
- 100 – DOS 히브리어 하드웨어 폰트 페이지 (IBM, HDOS [34]제외)
- 111 – DOS 그리스어(IBM 제외, AST Premium Exec DOS 5[35][36][37].0)
- 112 – DOS 터키어(IBM이 아닌 AST Premium Exec DOS 5.0[35][36][37])
- 113 – DOS 유고슬라비아어 (IBM 제외, AST Premium Exec DOS 5.0[35][36][37])
- 151 – DOS Nafitha 아랍어(IBM, ADOS 제외)
- 152 – DOS Nafitha 아랍어(IBM, ADOS 제외)
- 161 – DOS 아랍어(IBM, ADOS [34]제외)
- 162 – DOS 아랍어 (IBM, ADOS 제외)
- 163 – DOS 아랍어(IBM, ADOS [34]제외)
- 164 – DOS 아랍어 (IBM, ADOS 제외)
- 165 – DOS 아랍어(IBM, ADOS [34]제외)
- 166 – IBM 아랍어 PC (ADOS)[34]
- 210 – DEC DOS 그리스어 (NEC 제트메이트 프린터)
- 220 – DEC DOS 스페인어 (IBM 제외)
- 489 – 체코슬로바키아어 [OCR 소프트웨어 1993]
- 620 – DOS 폴란드어 (Mazovia) (IBM 제외)
- 667 – DOS 폴란드어 (Mazovia) (IBM 외)
- 668 – DOS 폴란드어 (IBM 이외)
- 706 – MS-DOS 서버 아랍어 Sakhr (IBM이 아닌 MSX 컴퓨터의 Sakhr 소프트웨어)
- 707 – MS-DOS 아랍어 Sakhr (IBM이 아닌 MSX 컴퓨터의 Sakhr 소프트웨어)
- 711 – MS-DOS 아랍어 Nafitha Enhanced (IBM 제외)
- 714 – MS-DOS 아랍어 Sakr (IBM 이외)
- 715 – MS-DOS 아랍어 APTEC (IBM사 제외)
- 721 – MS-DOS 아랍어 Nafitha International (IBM 이외)
- 768 – 아랍어 Al-Arabi (IBM이 아님)
- 770 – DOS 에스토니아어, 라트비아어[38], 리투아니아어 (리투아니아 리카 소프트웨어,[39] 리투아니아 RST 1095-89 국가 표준)
- 771 – DOS 리투아니아어/키릴어 - KBL[40] (리투아니아 Lika[39] 소프트웨어에서)
- 772 – DOS 리투아니아어/키릴어[41](리투아니아 Lika 소프트웨어,[39] 리투아니아 LST 1284:1993 국가 표준, 코드 페이지 1119로 IBM에 의해 채택됨
- 773 – DOS Latin-7 - KBL (리투아니아 Lika 소프트웨어에서)
- 774 – DOS 리투아니아어[42] (리투아니아 Lika 소프트웨어,[39] 리투아니아 LST 1283:1993 국가 표준, 코드 페이지 1118로 IBM에 의해 채택됨
- 775 – DOS Latin-7 Baltic Rim (리투아니아 Lika 소프트웨어,[39] 리투아니아 LST 1590-1 국가 표준, IBM과 Microsoft가 코드 페이지 775로 채택)
- 776 – DOS 리투아니아어 (확장 CP770)[43] (리투아니아 Lika 소프트웨어[39])
- 777 – DOS 악센트 리투아니아어 (구) (확장 CP773) - KBL[43] (리투아니아 Lika[39] 소프트웨어에서)
- 778 – DOS 악센트 리투아니아어 (확장 CP775)[43] (리투아니아 Lika 소프트웨어[39])
- 790 – DOS 폴란드어 (Mazovia)
- 854 – 스페인어[44][6]
- 881 – Latin 1(IBM 비탑재, AST Premium Exec DOS[35][36][37] 5.0)(IBM EBCDIC 881과의 경합 ID)
- 882 – Latin 2(ISO 8859-2) (IBM이 아닌 코드 페이지 912와 동일, AST Premium Exec DOS 5.0[35][36][37])(IBM EBCDIC 882와 충돌하는 ID)
- 883 – Latin 3(IBM 비탑재, AST Premium Exec DOS[35][36][37] 5.0)(IBM EBCDIC 883과의 충돌 ID)
- 884 – Latin 4(IBM 비탑재, AST Premium Exec DOS[35][36][37] 5.0)(IBM EBCDIC 884와의 충돌 ID)
- 885 – Latin 5(IBM이 아닌 AST Premium Exec DOS 5[35][36][37].0)(IBM EBCDIC 885와 충돌하는 ID)
- 895 – 체코어 (Kamenick†), (IBM사가 아닙니다.IBM CP895와의 경합ID - 7비트 EUC 일본어 로마자)
- 896 – DOS 폴란드어 (Mazovia) (IBM이 아닙니다.IBM CP896과의 경합 ID - 7비트 EUC 일본어 가타카나)
- 900 – DOS 러시아어(러시아어 MS-DOS 5.0 LCD).CPI)
- 928 – 그리스어(Star[45] 프린터), 그리스어 국가 표준 ELOT 928과 동일(IBM이 아님, IBM CP928과의 충돌 ID: 간체 중국어 PC DBCS)
- 966 – 사우디아라비아 (IBM사 제외)
- 991 – DOS 폴란드어 (Mazovia) (IBM 외)
- 999 – DOS Serbo-Croatian I (IBM이 아님), PC Nova 및 CroSC라고도 함II; 하부는 JUSI입니다.B1.002, 상부는 코드 페이지 437. 슬로베니아어 및 세르보크로아티아어 지원(라틴어 문자)
- 1001 – 아랍어 (Star[45] 프린터) (IBM이 아닌 IBM CP1001 - MICR과의 충돌 ID)
- 1261 – Windows Korean IBM-1261 LMBCS-17 (1363과 유사)
- 1270 – Windows 사미
- 2001 – 리투아니아 KBL (Star 프린터 상[45]), 코드 페이지 771과 동일
- 3001 – 에스토니아어 1 (Star[45] 프린터), 코드 페이지 1116과 동일
- 3002 – 에스토니아어 2 (Star[45] 프린터), 코드 페이지 922와 동일
- 3011 – 라트비아어 1 (Star[45] 프린터), 코드 페이지 437 - Latvian과 동일
- 3012 – Latvian-2 (Star[45] 프린터), 코드 페이지 866 - Latvian (Latvian RST 1040 - 90 National Standard )와 동일
- 3021 – 불가리아어 (스타[45] 프린터)MIK와 동일
- 3031 – 히브리어(Star 프린터[45]), 코드 페이지 862와 동일
- 3041 – Maltese (Star[45] 프린터) (ISO 646 Maltese와 동일)
- 3840 – IBM-Russian(Star 프린터 사용[45]), CP 866과 거의 동일
- 3841 – Gost-Russian (Star[45] 프린터), GOST 13052 및 중앙아시아 언어용 문자
- 3843 – 폴란드어 (Star 프린터 사용[45]), Mazovia와 동일
- 3844 – CS2 (Star[45] 프린터) (Kamenick과 동일)
- 3845 – 헝가리어(Star[45] 프린터), CWI와 동일
- 3846 – 터키어(별[45] 프린터), 코드 포인트 A8의 PC-8 터키어 + 오래된 터키 리라 기호(T))와 동일
- 3847 – 브라질-ABNT (Star 프린터 사용[45]), 브라질 국가표준 NBR-9614:1986과 동일
- 3848 – 브라질-ABICOMP(Star[45] 프린터), ABICOMP와 동일
- 3850 – 표준 KU(Star[45] 프린터), Kasetsart University의 태국어 인코딩 변형
- 3860 – Rajvitee KU (온스타[45] 프린터), Kasetsart University의 태국어 인코딩 변형
- 3861 – Microwiz KU (온스타[45] 프린터), Kasetsart University의 태국어 인코딩 변형
- 3863 – STD988 TIS (Star 프린터 상[45]), 태국어용 TIS 620 부호화 변형
- 3864 – 인기 있는 TIS (온스타[45] 프린터), 태국어용 TIS 620 인코딩의 종류
- 3865 – Newsic TIS (On[45] Star 프린터), 태국어용 TIS 620 인코딩 변형
- 28799 – FOCAL (스타[45] 프린터 상), FOCAL 문자 집합과 동일
- 28800 – HP RPL (Star[45] 프린터) (RPL과 동일)
- (번호 누락) – CWI-2(DOS용)는 헝가리어를 지원합니다.
- (번호 누락) – MIK(DOS용)는 불가리아어를 지원합니다.
- (번호 누락) – DOS Serbo-Croatian II, 슬로베니아어 및 Serbo-Croatian어 지원(라틴어 스크립트)
- (번호 누락) - 러시아어 대체 코드 페이지(DOS용), IBM CP 866의 원본입니다.
코드 페이지 할당 목록
알려진 코드 페이지 할당 목록(불완전):
| 아이디 | 이름 | 묘사 | 기원. | 플랫폼 | DOS | OS/2 | 창문들 | 맥 | 또 다른 | 부호화 | 댓글 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 없음 | 예약필 | IBM, Microsoft | 없음 | 3.3+ | 1.0+ | ? | ? | ? | 내부 OS[34] 사용 | |
| 437 | CP437, IBM437 | PC US | IBM[46] | IBM PC | 3.3+ | 1.0+ | 네. | ? | 네. | 8비트 SBCS | |
| 57344 - 61439 | 없음 | 개인사용파생상품 | IBM | 없음 | 없음 | 없음 | 없음 | 없음 | 없음 | 여러가지 | 개인용 코드 페이지 파생(E000h-EFFH) |
| 65280 - 65533 | 없음 | 개인 용도의 정의 | IBM | 없음 | 없음 | 없음 | 없음 | 없음 | 없음 | 여러가지 | 프라이빗 유스 코드 페이지 정의(FF00h-FFPDh) |
| 65534 | 없음 | 예약필 | IBM, Microsoft | 없음 | ? | ? | ? | ? | ? | 여러가지 | 내부 OS 사용(FFEh) |
| 65535 | 없음 | 예약필 | IBM, Microsoft | 없음 | 3.3+ | 1.0+ | ? | ? | ? | 여러가지 | 내부 OS 사용(FFFh)[34] |
비판
(Unicode와 달리) 많은 오래된 문자 인코딩에는 몇 가지 문제가 있습니다.일부 벤더는 코드 페이지에 있는 모든 코드 포인트 값의 의미를 충분히 문서화하고 있지 않기 때문에 다양한 컴퓨터 시스템을 통해 텍스트 데이터를 일관되게 처리하는 신뢰성이 떨어집니다.일부 벤더는 특정 코드 포인트 값을 추가하거나 변경하기 위해 확립된 코드 페이지에 고유 확장자를 추가합니다.예를 들어 Shift JIS의 바이트 0x5C는 플랫폼에 따라 백슬래시 또는 엔화 기호 중 하나를 나타낼 수 있습니다.마지막으로 Unicode를 사용하지 않는 프로그램에서 여러 언어를 지원하려면 각 문자열/문서에 사용되는 코드 페이지를 저장해야 합니다.
또, Windows-1252 의 텍스트에 ISO-8859-1 로 잘못 라벨 붙이는 일이 있습니다.이러한 코드 페이지의 유일한 차이점은 ISO-8859-1이 제어 문자에 사용하는 0x80~0x9F 범위의 코드 포인트 값이 Windows-1252에서 추가 인쇄 가능한 문자로 사용된다는 것입니다.특히 따옴표, 유로 기호 및 상표 기호에는 사용됩니다.Windows 이외의 플랫폼의 브라우저에서는, 이러한 문자의 빈 상자나 물음표가 표시되는 경향이 있기 때문에, 텍스트의 판독이 어려워집니다.대부분의 브라우저는 문자 집합을 무시하고 Windows-1252로 해석하여 이 문제를 해결했습니다.HTML5에서는 ISO-8859-1을 Windows-1252로 취급하는 것은 W3C 표준으로 [47]코드화되어 있습니다.브라우저는 일반적으로 이 동작을 처리하도록 프로그램되어 있지만 다른 소프트웨어에서는 항상 해당되지 않았습니다.따라서 Windows 시스템에서 파일 전송을 수신하면 Windows 이외의 플랫폼에서는 이러한 문자를 무시하거나 표준 제어 문자로 취급하여 지정된 제어 액션을 수행하려고 합니다.
유니코드의 방대한 문서, 문자의 방대한 레퍼토리 및 문자의 안정성 정책 때문에 위에 열거된 문제는 유니코드의 관심사가 되지 않습니다.UTF-8(100만 개 이상의 코드 포인트를 부호화할 수 있음)은 인터넷에서의 [48][49]인기도 면에서 코드 페이지 방식을 대체했습니다.
개인 코드 페이지
PC의 역사 초기에 사용자가 문자 인코딩 요건을 충족하지 못한 경우 Terminate 및 Stay Resident 유틸리티를 사용하거나 BIOS EPROM을 재프로그래밍하여 개인 또는 로컬 코드 페이지가 생성되었습니다.경우에 따라서는 비공식 코드 페이지 번호(CP895 등)가 발명되기도 했습니다.
보다 다양한 문자 집합 지원을 이용할 수 있게 되자 대부분의 코드 페이지는 사용되지 않게 되었습니다.단, 체코어 및 슬로바키아어 알파벳의 Kamenick™ 또는 KEYBCS2 인코딩 등의 예외가 있습니다.또 다른 문자 집합은 이란 시스템사가 페르시아어 지원을 위해 만든 이란 시스템 인코딩 표준이다.이 표준은 이란에서 DOS 기반 프로그램에서 사용되었으며 마이크로소프트 코드 페이지 1256이 도입된 후 사용되지 않게 되었습니다.그러나 이 인코딩을 사용하는 일부 Windows 및 DOS 프로그램은 여전히 사용 중이며 이 인코딩을 사용하는 일부 Windows 글꼴이 있습니다.
이러한 문제를 해결하기 위해 IBM 문자 데이터 표현 아키텍처 레벨 2는 사용자 정의 및 개인 용도로 할당된 코드 페이지 ID 범위를 특별히 예약합니다.이러한 코드 페이지 ID 를 사용하는 경우는, 유저가 특별히 이 점에 주의하지 않는 한, 다른 시스템 구성이나 다른 디바이스 또는 시스템에 같은 기능이나 외관을 재현할 수 있다고는 생각할 수 없습니다.코드 페이지 범위는 57344-61439 입니다.E000h-EFFH)는 공식적으로 사용자 정의 가능한 코드 페이지(또는 IBM CDRA의 경우 실제 CCSID)용으로 예약되어 있으며, 범위 65280~65533(FF00h~FFDH)은 사용자 정의 가능한 "개인용" 할당용으로 예약되어 있습니다.예를 들어, 코드 페이지 437(1B5h) 또는 28591(6FAF)의 미등록 커스텀 배리언트는, 다른 할당과의 경합을 회피해, 원래의 코드 페이지의 할당으로 기존의 내부 수치 로직을 유지하기 위해서, 각각 57781(E1B5h) 또는 61359(EFAFh)가 됩니다.기존 코드 페이지를 기반으로 하지 않은 미등록 개인 코드 페이지, 시스템에 대한 주소 지정이 가능한 논리 핸들만 필요한 프린터 글꼴과 같은 디바이스별 코드 페이지, 자주 변경되는 다운로드 글꼴 또는 로컬 환경에서 상징적인 의미를 가진 코드 페이지 번호에는 다음과 같은 개인 범위가 할당될 수 있습니다.65280 (FF00h)
코드 페이지 ID 0, 65534(FFEh) 및 65535(FFFh)는 DOS 등의 운영시스템에 의해 내부용으로 예약되어 있어 특정 코드페이지에 할당되어 있지 않습니다.
「 」를 참조해 주세요.
- Windows 코드 페이지
- 문자 부호화
- CCSID IBM의 공식 "코드 페이지" 정의 및 할당
- 코드 페이지 스니핑
- 유니코드
레퍼런스
- ^ "Contents". www.ibm.com.
- ^ "Code Page". sap.com. Archived from the original on 2009-11-14. Retrieved 2009-08-08.
- ^ a b "Glossary". oracle.com. Archived from the original on 2011-09-30. Retrieved 2009-08-08.
- ^ "VT510 Video Terminal Programmer Information". Digital Equipment Corporation (DEC). 7.1. Character Sets - Overview. Archived from the original on 2016-01-26. Retrieved 2017-02-15.
In addition to traditional DEC and ISO character sets, which conform to the structure and rules of ISO 2022, the VT510 supports a number of IBM PC code pages (page numbers in IBM's standard character set manual) in PCTerm mode to emulate the console terminal of industry-standard PCs.
- ^ "7.1. Character Sets - Overview". VT520/VT525 Video Terminal Programmer Information (PDF). Digital Equipment Corporation (DEC). July 1994. p. 7-1. EK-VT520-RM. A01. Archived (PDF) from the original on 2017-02-15. Retrieved 2017-02-15.
In addition to traditional DEC and ISO character sets the VT520 supports a number of IBM PC code pages (which refer to page numbers in IBM's standard character set manual) in PCTerm mode to emulate the console terminal of industry-standard PCs.
- ^ a b c Paul, Matthias R. (2001-06-10) [1995]. "Overview on DOS, OS/2, and Windows codepages" (CODEPAGE.LST file) (1.59 preliminary ed.). Archived from the original on 2016-04-20. Retrieved 2016-08-20.
- ^ "Printer Command Language Symbol Sets". www.pclviewer.com. Archived from the original on 2020-07-31. Retrieved 2021-05-25.
- ^ "HP Symbol Sets". pclhelp.com. Archived from the original on 2015-02-19. Retrieved 2017-02-20.
- ^ "PCL5 Camparison Guide" (PDF). Archived (PDF) from the original on 2017-02-21. Retrieved 2017-02-20.
- ^ Zbikowski, 마크, 앨런, 폴, 발머, 스티브, 보먼 판사, 르우벤, 보먼 판사, 롭, 버틀러, 존은 캐롤, 척이며, 마크, 첼, 데이비드. Colee, 마이크, 코트니, 마이크;Dryfoos, 마이크, 던컨, 레이첼, Eckhardt, 커트, 에번스, 에릭, 농부, 릭, 게이츠, 빌, 기어리, 마이클 그리핀, 밥. 호가스, 더그. 존슨, 제임스 W.;Kermaani, Kaamel, 왕, Adrian은;. 코흐, 리드, 란도브스키, 제임스 라슨, 크리스, 레넌, 토머스, Lipkie, 댄, 맥도날드, 마크, 맥키니, 브루스, 마틴, 파스칼, Mathers가, 에스텔. Matthews, 밥, Melin, 데이비드. Mergentime, Charles:네빈, 랜디, 뉴웰, 댄, 뉴웰, 타니, 노리스, 데이비드, 있을 때 오리어리, 마이크;O'Rear, 밥, 올손, 마이크;Osterman, 래리, Ostling, 리지, 빠이, 선일. 패터슨, 팀;P.에레즈, 게리, 피터스, 크리스, 페쫄트, Charles:폴록, 존은 레이놀즈, 아론, 루빈은 대릴, 라이언, 랠프, Schulmeisters, 칼, 샤, Rajen, 쇼, 배리, 쇼트, 앤서니, Slivka, 벤, Smirl, 존, Stillmaker, 베티, 스토다드, 존은 틸먼, 데니스..휘튼, 그렉, Yount, 나탈리. Zeck, 스티브(1988년)."기술 고문".그 MS-DOS백과 사전:버전 1.03.2를 통해.덩컨, 레이, 보츠윅, 스티브, 버고인, 키스, 바이어스, 로버트 A.;까지.호건, 톰, 카일, 짐,. Letwin, 고든, 페쫄트, Charles:라비, 칩, 톰린, 짐, 윌턴 양탄자, 리처드, 울버 턴, 반, 웡은 윌리엄;우드콕. 도요목 도요과의 조류., JoAnne(완전히 교육 reworked.).워싱턴 주, 미국:MicrosoftPress.아이 에스비엔 1-55615-049-0. LCCN 87-21452.OCLC 16581341.[1]는 승객을 머신(xix+1570 페이지, 26))(NB에서 2018-10-14 Archived.이 판은 다른 작가 팀에 의해 철회된 1986년 초판을 광범위하게 수정한 후 1988년에 발행되었다.)
- ^ "Code Page Identifiers". microsoft.com. Microsoft. Archived from the original on 2014-10-27. Retrieved 2014-10-27.
- ^ "VGA/SVGA Video Programming--VGA Text Mode Operation". osdever.net. Archived from the original on 2010-09-01. Retrieved 2006-09-23.
- ^ "IBM i Globalization: Code Pages". IBM. Archived from the original on 2012-07-16.
- ^ a b c d e f xlate - Transliterate Contents of Records, IBM Corporation, 2010 [1986], archived from the original on 2019-06-16, retrieved 2016-10-18
- ^ "Code Page CPGID 01093 (pdf)" (PDF). Archived from the original (PDF) on 2015-07-08.
- ^ Paul, Matthias R. (2001-06-10) [1995]. "Format description of DOS, OS/2, and Windows NT .CPI, and Linux .CP files" (CPI.LST file) (1.30 ed.). Archived from the original on 2016-04-20. Retrieved 2016-08-20.
- ^ Elliott, John C. (2006-10-14). "CPI file format". Seasip.info. Archived from the original on 2016-09-22. Retrieved 2016-09-22.
- ^ Brouwer, Andries Evert (2001-02-10). "CPI fonts". 0.2. Archived from the original on 2016-09-22. Retrieved 2016-09-22.
- ^ Haralambous, Yannis (September 2007). Fonts & Encodings. Translated by Horne, P. Scott (1 ed.). Sebastopol, California, USA: O'Reilly Media, Inc. pp. 601–602, 611. ISBN 978-0-596-10242-5.
- ^ MS-DOS Programmer's Reference. Microsoft Press. 1991. ISBN 1-55615-329-5.
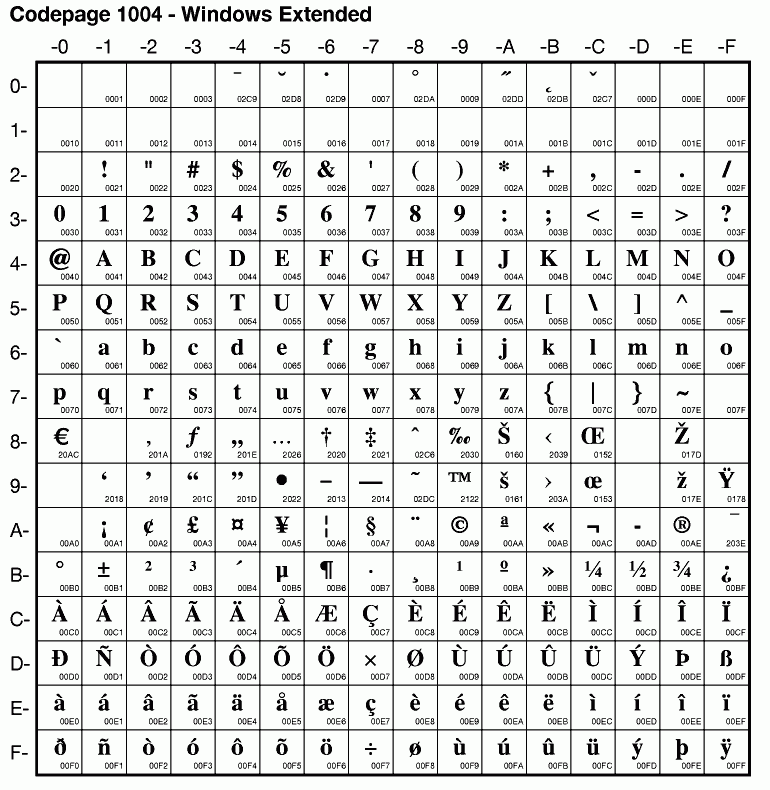
- ^ "Codepage 1004 - Windows Extended". IBM. 2001. Archived from the original on 2018-05-13. Retrieved 2018-05-13.
- ^ "Character Data Representation Architecture". Archived from the original on 2019-06-23. Retrieved 2019-10-12.
- ^ a b c d e f g h i j k l "IBM Coded Character Set Identifier (CCSID)". IBM. Archived from the original on 2009-11-26.
- ^ ISO/IEC 8859-1:1998(E). ISO. 1998-04-15. p. 1. Archived from the original on 2020-10-30. Retrieved 2020-10-30.
The coded characters in this set may be used in conjunction with coded control functions selected from ISO/IEC 6429.
- ^ "Code Pages". microsoft.com. Microsoft. Archived from the original on 2011-02-27. Retrieved 2010-12-21.
- ^ "pentaho/pentaho-reporting". GitHub. Archived from the original on 2019-06-16. Retrieved 2017-02-20.
- ^ a b c d e "Code Page Identifiers". Microsoft Developer Network. Microsoft. 2014. Archived from the original on 2016-06-19. Retrieved 2016-06-19.
- ^ a b c d e "Web Encodings - Internet Explorer - Encodings". WHATWG Wiki. 2012-10-23. Archived from the original on 2016-06-20. Retrieved 2016-06-20.
- ^ Foller, Antonin (2014) [2011]. "Western European (IA5) encoding - Windows charsets". WUtils.com - Online web utility and help. Motobit Software. Archived from the original on 2016-06-20. Retrieved 2016-06-20.
- ^ Foller, Antonin (2014) [2011]. "German (IA5) encoding - Windows charsets". WUtils.com - Online web utility and help. Motobit Software. Archived from the original on 2016-06-20. Retrieved 2016-06-20.
- ^ Foller, Antonin (2014) [2011]. "Swedish (IA5) encoding - Windows charsets". WUtils.com - Online web utility and help. Motobit Software. Archived from the original on 2016-06-20. Retrieved 2016-06-20.
- ^ Foller, Antonin (2014) [2011]. "Norwegian (IA5) encoding - Windows charsets". WUtils.com - Online web utility and help. Motobit Software. Archived from the original on 2016-06-20. Retrieved 2016-06-20.
- ^ Foller, Antonin (2014) [2011]. "US-ASCII encoding - Windows charsets". WUtils.com - Online web utility and help. Motobit Software. Archived from the original on 2016-06-20. Retrieved 2016-06-20.
- ^ a b c d e f g Paul, Matthias R. (2002-09-05), Technical info on undocumented DOS country info for LCASE, ARAMODE and CCTORC records, FreeDOS development list fd-dev at Topica, archived from the original on 2016-05-27, retrieved 2016-05-26
- ^ a b c d e f g h Brown, Ralf D. (2002-12-29). The x86 Interrupt List. 61.
- ^ a b c d e f g h Paul, Matthias R. (1997-07-30). NWDOS-TIPs — Tips & Tricks rund um Novell DOS 7, mit Blick auf undokumentierte Details, Bugs und Workarounds. MPDOSTIP. Release 157 (in German) (3 ed.). Archived from the original on 2016-05-22. Retrieved 2012-01-11. (NB. NWDOSTIP).TXT는 Novell DOS 7 및 OpenDOS 7.01에 관한 포괄적인 작업이며, 문서화되어 있지 않은 많은 기능 및 내부 기능에 대한 설명을 포함합니다.저자의 더 큰 MPDOSTIP.Z의 일부입니다.IP 수집은 최대 2001년까지 유지되며 동시에 많은 사이트에 배포되었습니다.제공된 링크는 HTML 변환된 이전 버전의 NWDOSTIP를 가리키고 있습니다.TXT 파일).
- ^ a b c d e f g h Paul, Matthias R. (2001-04-09). NWDOS-TIPs — Tips & Tricks rund um Novell DOS 7, mit Blick auf undokumentierte Details, Bugs und Workarounds. MPDOSTIP. Release 183 (in German) (3 ed.).
- ^ "770". Archived from the original on 2017-02-26. Retrieved 2017-02-25. 리투아니아 Lika 소프트웨어에서
- ^ a b c d e f g h "LIKIT". www.likit.lt. Archived from the original on 2017-04-19. Retrieved 2017-02-25.
- ^ "771". Archived from the original on 2017-02-26. Retrieved 2017-02-25. 리투아니아 Lika 소프트웨어에서
- ^ "772". Archived from the original on 2017-02-26. Retrieved 2017-02-25. 리투아니아 Lika 소프트웨어에서
- ^ "774". Archived from the original on 2017-02-26. Retrieved 2017-02-25. 리투아니아 Lika 소프트웨어에서
- ^ a b c "lietuvybė.lt - Rašmenų koduotės" [lietuvybė.lt - Character encodings] (in Lithuanian). Archived from the original on 2019-08-28. Retrieved 2019-08-28.
- ^ Hogan, Thom (1992). Die PC-Referenz für Programmierer (in German) (2 ed.). Systhema Verlag GmbH. ISBN 3-89390-272-4. (NB. 이 책은 Microsoft Press의 "The Programmer's PC Sourcebook"을 독일어로 번역한 것입니다.스페인의 코드 페이지 ID 854가 기재되어 있습니다).
- ^ a b c d e f g h i j k l m n o p q r s t u v w x y z "Star LC 8021 User's Manual" (PDF). Archived (PDF) from the original on 2020-09-29. Retrieved 2017-02-20.
- ^ IBM. "SBCS code page information document - CPGID 00437". Archived from the original on 2016-06-09. Retrieved 2014-07-04.
- ^ "Encoding". WHATWG. 2015-01-27. sec. 4.2 Names and labels. Archived from the original on 2015-02-04. Retrieved 2015-02-04.
- ^ "Usage Statistics of Character Encodings for Websites, (updated daily)". w3techs.com. Retrieved 2015-08-06.
- ^ "UTF-8 Usage Statistics". trends.builtwith.com. Archived from the original on 2011-03-24. Retrieved 2011-03-28.
외부 링크
- IBM CDRA 용어집
- Wayback Machine의 IBM 코드 페이지(2016-02-05)
- Wayback Machine의 인코딩 체계별 IBM 코드 페이지(2009-09-06)
- IBM/ICU 문자 집합 정보
- Microsoft 코드 페이지 식별자(Microsoft 목록에는 Windows의 일반 응용 프로그램에서 활발하게 사용되는 코드 페이지만 포함되어 있습니다.지원되는 코드 페이지의 전체 목록은 Torsten Mohrin 목록도 참조하십시오.)
- ANSI 코드 페이지 및 OEM 코드 페이지만 포함하지만 Wayback Machine에서 각 페이지에 대한 자세한 링크를 포함하는 Microsoft 목록(2012-10-23)
- 버튼을 누르면 문자 집합 및 코드 페이지
- Microsoft Chcp 명령어:콘솔 활성 코드 페이지 표시 및 설정
| 초기 통신 | |
|---|---|
| ISO/IEC 8859 |
|
| 서지학적 용도 | |
| 국가 표준 | |
| ISO/IEC 2022 | |
| Mac OS 코드 페이지 ("구체") | |
| DOS 코드 페이지 | |
| IBM AIX 코드 페이지 | |
| Windows 코드 페이지 | |
| EBCDIC 코드 페이지 | |
| DEC 단자(VTX) | |
| 플랫폼 고유의 |
|
| Unicode/ISO/IEC 10646 | |
| TeX 조판 시스템 | |
| 기타 코드 페이지 | |
| 제어 문자 | |
| 관련 토픽 | |

{kind=link}
{kind=link}