차세대 그래픽스 코어
Graphics Core Next이 글은 그 주제에 익숙하지 않은 사람들에게는 불충분한 맥락을 제공한다.에게더 에 을 . (2020년 10월 ( 템플릿메시지 및 ) |
Graphics Core Next(GCN)[1]는 TeraScale 마이크로아키텍처의 후속으로 AMD가 GPU용으로 개발한 일련의 마이크로아키텍처와 명령어 세트아키텍처의 코드명입니다.GCN을 탑재한 최초의 제품은 2012년 [2]1월 9일에 출시되었습니다.
GCN은 TeraScale의 [3]매우 긴 명령어 SIMD 아키텍처와 대조되는 축소 명령어 세트 SIMD 마이크로 아키텍처입니다.GCN은 TeraScale보다 훨씬 더 많은 트랜지스터를 필요로 하지만 컴파일러가 더 단순하기 때문에 범용 GPU(General Purpose GPU) 계산에 이점을 제공합니다.
GCN 그래픽 칩은 별도로 출시된 AMD의 Radeon HD 7000, HD 8000, 200, 300, 400, 500 및 베가 시리즈의 그래픽 카드 중 일부 모델에서 사용 가능한 28nm의 CMOS와 14nm(삼성전자 및 GlobalFoundries) 및 7nm(TSMC)의 FinFET를 사용하여 제작되었습니다.GCN은 PlayStation 4 및 Xbox One과 같은 APU(가속 처리 장치)의 그래픽 부분에서도 사용되었습니다.
명령 집합
GCN 명령 세트는 AMD가 소유하고 있으며 GPU 전용으로 개발되었습니다.분할을 위한 미세 조작은 없습니다.
매뉴얼은 다음 경우에 이용 가능합니다.
- 그래픽스 코어 Next 1 명령 세트,
- 그래픽스 코어 Next 2 명령 세트,
- Graphics Core Next 3 및 4 명령어 세트
- Graphics Core Next 5 명령어 세트 및
- "Vega" 7nm 명령 세트 아키텍처(Graphics Core Next 5.1이라고도 함).
GCN 명령 세트에는 LLVM 컴파일러 [5]백엔드를 사용할 수 있습니다.메사 3D에서 사용됩니다.
GNU 컴파일러 컬렉션 9는 2019년부터[6] 싱글 스레드 독립형 프로그램을 위해 GCN 3과 GCN 5를 지원하며 GCC 10도 OpenMP와 OpenACC를 [7]통해 오프로드됩니다.
MIAOW는 AMD Southern Islands GPGPU 마이크로아키텍처의 오픈 소스 RTL 구현입니다.
2015년 11월 AMD는 CUDA 기반 애플리케이션을 공통 C++ 프로그래밍 [8]모델로 이식하는 것을 목표로 하는 Boltzmann Initiative를 발표했습니다.
AMD는 Super Computing 15 이벤트에서 클러스터 클래스의 고성능 컴퓨팅용 헤드리스 Linux 드라이버 및 HSA 런타임 인프라스트럭처인 HCC(Hetheryput Compute Compute Compiler)와 앞서 언급한 공통 C++ 모델로 CUDA 애플리케이션을 이식하기 위한 HIP(Hetheryput Interface for Portability) 툴을 전시했습니다.
마이크로아키텍처
2017년 7월 현재 Graphics Core Next 명령어 세트는 5회 반복되고 있습니다.첫 번째 4세대 간의 차이는 미미하지만 5세대 GCN 아키텍처는 성능을 향상시키고 하나의 고정밀 [9]번호 대신 2개의 고정밀 번호를 동시에 처리할 수 있도록 대폭 변경된 스트림 프로세서를 갖추고 있습니다.
명령어 처리

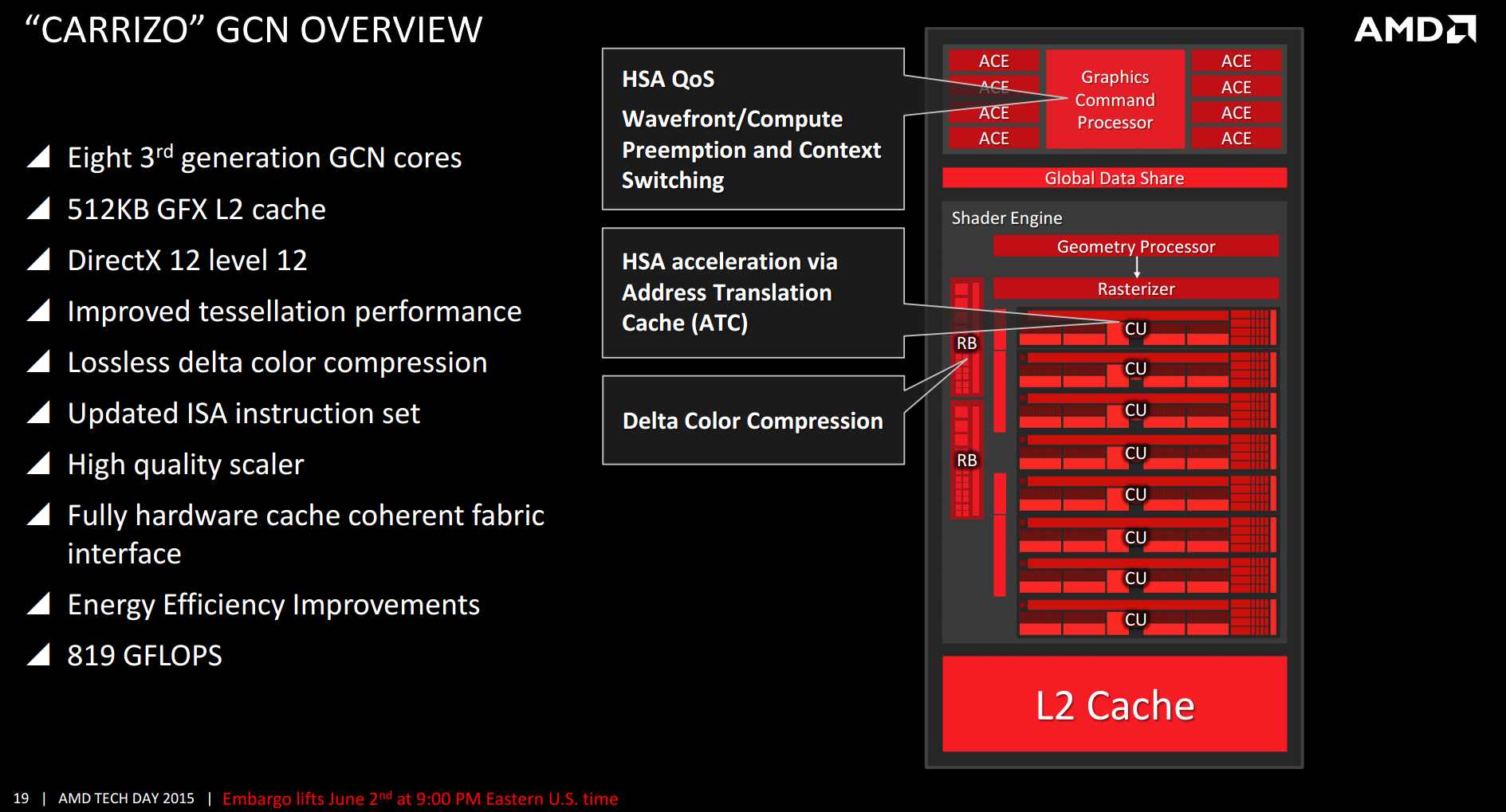
그래픽스 명령어 프로세서
그래픽스 커맨드 프로세서(GCP)는, GCN 마이크로 아키텍쳐(architecture)의 기능 유닛입니다.다른 작업 중에서도 비동기 [10]셰이더 처리를 담당합니다.
비동기 컴퓨팅 엔진
ACE(Asynchronous Compute Engine)는 그래픽스 명령어 [ambiguous]프로세서와 유사한 기능을 하는 블록 서비스 컴퓨팅용입니다.
스케줄러
GCN의 세 번째 반복 이후 하드웨어에는 셰이더 실행 중 "웨이브론트"를 스케줄링하는 스케줄러(CU Scheduler 또는 Compute Unit Scheduler)와 드로우 큐 및 컴퓨팅 큐 실행을 스케줄링하는 스케줄러 2개가 포함되어 있습니다.후자는 고정 함수 파이프라인 속도 또는 대역폭에 의해 제한된 그래픽 명령으로 인해 컴퓨팅 유닛(CU)이 충분히 활용되지 않을 때 컴퓨팅 작업을 실행함으로써 성능을 향상시킵니다.이 기능을 비동기 컴퓨팅이라고 합니다.
특정 셰이더에 대해 GPU 드라이버는 지연을 최소화하기 위해 CPU에 대한 명령을 스케줄링할 수도 있습니다.
기하학 프로세서

지오메트리 프로세서에는 지오메트리 어셈블러, 테셀레이터 및 정점 어셈블러가 포함되어 있습니다.
Teselator는 Direct3D 11 및 OpenGL 4.5(2017년 [11]1월 21일 AMD 참조)에서 정의된 하드웨어 테셀레이션을 수행할 수 있으며, ATI TruForm 및 하드웨어 테셀레이션을 AMD의 최신 반도체 지적 재산 핵심으로 성공했습니다.
계산 단위
1개의 컴퓨팅 유닛(CU)은 64개의 셰이더 프로세서와 4개의 텍스처 매핑 유닛(TMU)[12][13]을 조합합니다.계산 단위는 ROP(Render Output Unit)와는 별개이지만 ROP([13]Render Output Unit)에 공급됩니다.각 컴퓨팅 유닛은 다음과 같이 구성됩니다.
- CU 스케줄러
- 브랜치&메시지
- 16레인 폭의 SIMD 벡터 유닛(SIMD-VU)×4
- 64 KiB 벡터 범용 레지스터(VGPR) 파일x 4
- 1 스칼라 유닛(SU)
- 4KiB GPR 파일
- 64KiB의 로컬 데이터 공유
- 4 텍스처 필터 유닛
- 16 텍스처 가져오기 로드/저장 단위
- 16 KiB 레벨 1(L1) 캐시
4개의 컴퓨팅 유닛은 16KiB L1 명령 캐시와 32KiB L1 데이터 캐시를 공유하도록 배선되어 있으며, 둘 다 읽기 전용입니다.SIMD-VU는 한 번에 16개의 요소(사이클당)로 동작하지만 SU는 한 번에 1개(1사이클당)로 동작할 수 있습니다.게다가 SU는 [14]브랜치등의 다른 조작을 처리합니다.
모든 SIMD-VU에는 레지스터를 저장하는 개인 메모리가 있습니다.레지스터에는 각각 4바이트 번호를 보유하는 스칼라 레지스터(S0, S1 등)와 64개의 4바이트 번호 세트를 나타내는 벡터 레지스터(V0, V1 등)의 2종류가 있습니다.벡터 레지스터에서는 모든 연산이 64개의 숫자에 대해 병렬로 수행됩니다.64개의 입력에 대응합니다.예를 들어, 한 번에 64개의 다른 픽셀로 동작할 수 있습니다(각 픽셀의 입력은 조금씩 다르므로 마지막에 약간 다른 색상이 표시됩니다).
모든 SIMD-VU에는 512개의 스칼라 레지스터와 256개의 벡터 레지스터를 저장할 수 있는 공간이 있습니다.
CU 스케줄러
CU 스케줄러는 하드웨어 기능 블록으로 SIMD-VU가 실행할 웨이브프론을 선택합니다.스케줄링을 위해 사이클마다 1개의 SIMD-VU를 선택합니다.이는 다른 하드웨어 또는 소프트웨어 스케줄러와 혼동하지 마십시오.
웨이브프런트
셰이더는 그래픽 처리를 수행하는 GLSL로 작성된 작은 프로그램이고 커널은 GPGPU 처리를 수행하는 OpenCL로 작성된 작은 프로그램입니다.이러한 프로세스에서는 그리 많은 레지스터가 필요하지 않지만 시스템 또는 그래픽 메모리에서 데이터를 로드해야 합니다.이 작업에는 상당한 지연 시간이 수반됩니다.AMD와 Nvidia는 이 피할 수 없는 지연 시간, 즉 여러 스레드의 그룹화를 숨기기 위해 유사한 방법을 선택했습니다.AMD는 이러한 그룹을 "웨이브프런트"라고 부르는 반면, Nvidia는 "워프"라고 부릅니다.스레드 그룹은 지연 시간을 숨기기 위해 이 방법을 구현하는 GPU 스케줄링의 가장 기본적인 단위입니다.이는 SIMD 방식으로 처리되는 데이터의 최소 크기, 코드 실행 가능한 최소 단위, 그리고 그 안에 있는 모든 스레드에서 동시에 단일 명령을 처리하는 방법입니다.
모든 GCN GPU에서 "웨이브프런트"는 64개의 스레드로 구성되며, 모든 Nvidia GPU에서 "워프"는 32개의 스레드로 구성됩니다.
AMD의 솔루션은 각 SIMD-VU에 여러 개의 웨이브프론트를 부여하는 것입니다.하드웨어는 레지스터를 다른 웨이브프론트에 배포하고, 한 웨이브프론트가 메모리에 있는 어떤 결과를 기다리고 있을 때 CU 스케줄러는 SIMD-VU에 다른 웨이브프론트를 할당합니다.웨이브프론트는 SIMD-VU마다 귀속됩니다.SIMD-VU는 웨이브프론트를 교환하지 않습니다.SIMD-VU당 최대 10개의 웨이브프론트를 설정할 수 있습니다(따라서 CU당 40개).
AMD CodeXL은 SGPR과 VGPR의 수와 웨이브프론트 수의 관계를 나타내는 테이블을 나타내고 있지만 기본적으로 SGPRS의 경우 웨이브프론트 수당 104~512 사이이며 VGPRS의 경우 웨이브프론트 수당 256입니다.
SSE 지침과 함께 가장 기본적인 병렬화 개념을 종종 "벡터 폭"이라고 부릅니다.벡터 폭은 벡터 폭의 총 비트 수로 특징지어집니다.
SIMD 벡터 유닛
각 SIMD 벡터 유닛에는 다음이 있습니다.
- 16레인 정수와 부동소수점 벡터 산술 논리 유닛(ALU)
- 64 KiB Vector General Purpose Register(VGPR) 파일
- 48비트 프로그램 카운터
- 10 Wavefront 명령버퍼(각 Wavefront는 64 스레드의 그룹 또는 1개의 논리 VGPR 크기)
- 16레인 SIMD 유닛에 4사이클에 걸쳐 64스레드 파면 문제가 발생함
각 SIMD-VU에는 10개의 파면 명령 버퍼가 있으며, 1개의 파면을 실행하는 데 4개의 사이클이 소요됩니다.
오디오 및 비디오 액셀러레이션 블록
GCN의 많은 구현에는 일반적으로 AMD의 다른 ASIC 블록이 포함되어 있습니다.Unified Video Decoder, Video Coding Engine 및 AMD TrueAudio를 포함하지만 이에 한정되지 않습니다.
비디오 코딩 엔진
Video Coding Engine은 Radeon HD 7000 [15]시리즈에 처음 도입된 비디오 부호화 ASIC입니다.
VCE의 초기 버전에서는 SVE 임시 인코딩 및 디스플레이 인코딩 모드와 함께 YUV420 픽셀 형식의 I 및 P 프레임 H.264 인코딩 지원이 추가되었으며, 두 번째 버전에서는 YUV420 및 YUV444 I 프레임에 대한 B 프레임 지원이 추가되었습니다.
VCE 3.0은 고품질 비디오 스케일링과 HEVC(H.265) 코덱을 추가하여 3세대 GCN의 일부를 형성했습니다.
VCE 4.0은 베가 아키텍처의 일부였고, 그 후 비디오 코어 넥스트에 의해 계승되었습니다.
True Audio
이 섹션은 비어 있습니다.추가하시면 됩니다. (2018년 8월) |
통합 가상 메모리
2011년 프리뷰에서 AnandTech는 Graphics Core [16]Next가 지원하는 통합 가상 메모리에 대해 기술했습니다.



![AMD APUs with GCN graphics gain from unified main memory conserving scarce bandwidth.[17]](/wiki/File:HSA-enabled_integrated_graphics.svg)
이기종 시스템 아키텍처(HSA)

하드웨어에 실장되어 있는 특정 HSA 기능의 일부는 운영체제의 커널(서브시스템) 및/또는 특정 디바이스 드라이버로부터의 지원이 필요합니다.예를 들어 2014년 7월에 AMD는 Graphics Core Next 기반 Radeon 그래픽 카드를 지원하기 위해 Linux 커널 메인라인 3.17에 통합되는 83개의 패치 세트를 발표했습니다.이른바 HSA 커널 드라이버는 /drivers/gpu/hsa 디렉토리에 존재하며 DRM 그래픽 디바이스 드라이버는 /drivers/gpu/drm에[19] 존재하며 기존 Radeon [20]카드용 DRM 드라이버를 확장합니다.이 첫 번째 구현은 단일 "Kaveri" APU에 중점을 두고 기존 Radeon 커널 그래픽 드라이버(kgd)와 함께 작동합니다.
무손실 델타 색 압축
이 섹션은 확장해야 합니다.추가하시면 됩니다. (2018년 8월) |
하드웨어 스케줄러
하드웨어 스케줄러는 스케줄링을 수행하고[21] 드라이버에서 하드웨어로 컴퓨팅 큐 할당을 오프로드하기 위해 사용됩니다.이러한 큐는 적어도1개의 ACE에 빈 큐가 존재할 때까지 버퍼링됩니다.이로 인해 모든 큐가 꽉 차거나 안전하게 [22]할당하는 큐가 없어질 때까지 HWS는 버퍼링된 큐를 ACE에 즉시 할당합니다.
실행되는 스케줄링 작업의 일부에는 우선순위가 높은 큐가 포함되어 있습니다.이 큐는 우선순위가 낮은 태스크를 다른 태스크보다 우선순위가 높은 태스크로 실행할 필요가 없기 때문에 우선순위가 높은 태스크는 가능한 한 GPU를 독점하도록 스케줄된 우선순위가 높은 태스크와 동시에 실행할 수 있습니다.다른 태스크가 우선 순위가 높은 태스크가 [21]사용하지 않는 리소스를 사용하도록 허용합니다.이들은 기본적으로 디스패치 [21]컨트롤러가 없는 비동기 컴퓨팅 엔진입니다.4세대 GCN 마이크로아키텍처에 처음 도입되었지만 [23]내부 테스트 목적으로 [21]3세대 GCN 마이크로아키텍처에 도입되었습니다.드라이버 업데이트를 통해 3세대 GCN 부품의 하드웨어 스케줄러가 실가동 [21]환경에서 사용할 수 있게 되었습니다.
원시 폐기 액셀러레이터
이 유닛은 정점 셰이더에 들어가기 전에 퇴화 삼각형을 폐기하고 프래그먼트 [24]셰이더에 들어가기 전에 프래그먼트를 덮지 않는 삼각형을 폐기합니다.이 유닛은 4세대 GCN 마이크로아키텍처와 [24]함께 도입되었습니다.
세대
그래픽스 코어 Next 1
| 발매일 | 2012년 1월, 전([citation needed]) |
|---|---|
| 역사 | |
| 전임자 | 테라스케일 3 |
| 후계자 | 그래픽스 코어 Next 2 |
GCN 1 마이크로아키텍처는 여러 Rade on HD 7000 시리즈 그래픽 카드로 사용되었습니다.
.jpg)
- CPU 및[16] GPU용 통합 주소 공간을 사용하여 64비트 주소 지정(x86-64 주소 공간) 지원
- DirectX 및 OpenGL 확장 기능을 통해 가상 메모리 지원을 가능하게 하는 부분 상주 텍스처 [26]지원
- AMD 전원튜닝 지원: 특정 TDP[27] 내에서 성능을 유지하도록 동적으로 조정
- 맨틀(API) 지원
계산과 [14][28]디스패치를 제어하는 비동기 컴퓨팅 엔진이 있습니다.
제로코어 파워
제로코어 파워는 장시간 아이돌 전력 절약 테크놀로지입니다.[29]사용하지 않을 때는 GPU의 기능 유닛을 정지합니다.AMD ZeroCore Power 테크놀로지는 AMD PowerTune을 보완합니다.
칩스
디스크리트 GPU(남부 아일랜드 패밀리):
- 올란드
- 카보베르데
- 핏케언
- 타히티
그래픽스 코어 Next 2
| 발매일 | 2013년, 전([citation needed]) |
|---|---|
| 역사 | |
| 전임자 | 그래픽스 코어 Next 1 |
| 후계자 | 그래픽스 코어 Next 3 |


2세대 GCN은 Radeon HD 7790과 함께 도입되었으며 Radeon HD 8770, R7 260/260X, R9 290/290X, R9 295X2, R7 360 및 R9 390/390X에도 탑재되어 있습니다.FreeSync 지원, AMD TrueAudio 및 AMD Power 개정판 등 기존 GCN에 비해 여러 가지 이점이 있습니다.테크놀로지를 조정.
GCN 2세대는 '쉐이더 엔진'(SE)이라는 엔티티를 선보였다.셰이더 엔진은 1개의 지오메트리 프로세서, 최대 44개의 CU(Hawaii 칩), 래스터라이저, ROP 및 L1 캐시로 구성됩니다.쉐이더 엔진에는 그래픽스 명령어프로세서, 8개의 ACE, L2 캐시 및 메모리 컨트롤러, 오디오 및 비디오 액셀러레이터, 디스플레이 컨트롤러, 2개의 DMA 컨트롤러 및 PCIe 인터페이스가 포함되어 있지 않습니다.
A10-7850K "Kaveri"에는 독립 스케줄링 및 [30]작업 항목 디스패치를 위한 8개의 CU(컴퓨팅 유닛)와 8개의 비동기 컴퓨팅 엔진이 포함되어 있습니다.
2013년 11월 AMD Developer Summit(APU)에서 Michael Mantor는 Radeon R9 290X를 [31]발표했습니다.
칩스
전용 GPU(Sea Islands 패밀리):
- 보네르
- 하와이
APU에 통합:
- 테마시
- 카비니
- 리버풀(PlayStation 4에서 발견된 APU)
- Durango(Xbox One 및 Xbox One S에 있는 APU)
- 카베리
- 고다바리
- 멀린스
- 비마
- 카리조 L
그래픽스 코어 Next 3
| 발매일 | 2015년, 전([citation needed]) |
|---|---|
| 역사 | |
| 전임자 | 그래픽스 코어 Next 2 |
| 후계자 | 그래픽스 코어 Next 4 |

GCN 3generation[32]2014년의 라데온 R9 285과 R9 M295X는"통가"GPU에 있는 걸로 그것은 향상된 모자이크식 포장 성능, 무손실 델타 색 압축 메모리 대역 폭 사용, 그리고 더 효율적인 업데이트된 명령 집합, 영상을 위한 새로운 높은 품질 조절기, 그리고 새로운 멀티 미디어 엔진(비디오 염기를 줄이기 위해 특징 소개되었다.r/de코더) 델타 색 압축은 [33]Mesa에서 지원됩니다.하지만 이전 [34]세대에 비해 2배 정밀도가 떨어진다.
칩스
개별 GPU:
APU에 통합:
그래픽스 코어 Next 4
| 발매일 | 6월, 전([citation needed]) |
|---|---|
| 역사 | |
| 전임자 | 그래픽스 코어 Next 3 |
| 후계자 | 그래픽스 코어 Next 5 |


북극 제도 제품군의 GPU는 2016년 2분기에 AMD Radeon 400 시리즈와 함께 소개되었습니다.3D 엔진(GCA(Graphics and Compute Array) 또는 GFX)은 Tonga [36]칩과 동일합니다.그러나 Polaris는 새로운 디스플레이 컨트롤러 엔진, UVD 버전 6.3 등을 탑재하고 있다.
폴라리스 30을 제외한 모든 폴라리스 기반 칩은 삼성전자가 개발하고 GlobalFoundries에 [37]라이선스한 14nm 핀펫 공정에서 생산된다.약간 새로워진 Polaris 30은 Samsung과 GlobalFoundries가 개발한 12nm LP FinFET 프로세스 노드에 구축되었습니다.4세대 GCN 명령 집합 아키텍처는 3세대 GCN과 호환됩니다.14 nm FinFET 프로세스에 최적화되어 있어 3세대 [38]GCN보다 GPU 클럭 속도가 향상됩니다.아키텍처의 개량점에는 새로운 하드웨어 스케줄러, 새로운 원시 폐기 액셀러레이터, 새로운 디스플레이 컨트롤러 및 컬러 채널당 10비트로 초당 60프레임의 4K 해상도로 HEVC를 디코딩할 수 있는 업데이트된 UVD가 포함됩니다.
칩스
개별 GPU:[39]
- 'Rade on RX 470' 및 'Rade on RX 480' 브랜드 그래픽 카드에 탑재된 Polaris 10(코드네임 Ellesmere)
- 'Rade on RX 460' 브랜드 그래픽 카드(Rade on RX 560D)에 탑재된 Polaris 11(코드네임 배핀)
- 'Rade on RX 550' 및 'Rade on RX 540' 브랜드 그래픽 카드에 탑재된 Polaris 12(코드네임 Lexa)
- Polaris 20은 리프레쉬(14 nm LPP Samsung/Glo FinFET 프로세스) Polaris 10으로 클럭이 높아 'Rade on RX 570' 및 'Rade on RX 580' 브랜드 그래픽[40] 카드에 사용
- Polaris 21은 리프레쉬 (14 nm LPP Samsung/Glo FinFET 프로세스)Polaris 11로, "Rade on RX 560" 브랜드 그래픽 카드에 사용됩니다.
- Polaris 22, "Radeon RX Vega M GH" 및 "Radeon RX Vega M GL" 브랜드 그래픽 카드에 탑재(Kaby Lake-G의 일부)
- Polaris 23은 갱신(14 nm LPP Samsung/Glo FinFET 프로세스) Polaris 12로, 「Rade on Pro WX 3200」및 「Rade on RX 540X」브랜드 그래픽 카드(Rade on RX 640도)[41]에 사용됩니다.
- Polaris 30 (12 nm LP GloFinFET 프로세스)Polaris 20으로 클럭이 높아 'Rade on RX 590' 브랜드 그래픽 카드에[42] 사용
전용 GPU와 더불어 Polaris는 PlayStation 4 Pro와 Xbox One X의 APU에 각각 "Neo"와 "Scorpio"로 사용됩니다.
정밀도 높은 퍼포먼스
모든 GCN 4세대 GPU의 FP64 퍼포먼스는 16/ FP32 퍼포먼스입니다.
그래픽스 코어 Next 5
| 발매일 | 6월, 전([citation needed]) |
|---|---|
| 역사 | |
| 전임자 | 그래픽스 코어 Next 4 |
| 후계자 | RDNA 1 |

AMD는 2017년 [38][43][44]1월부터 차세대 컴퓨팅 유닛(Next-Generation Compute Unit)이라고 불리는 차세대 GCN 아키텍처의 세부사항을 공개하기 시작했습니다.새로운 설계에서는 클럭당 명령 수가 증가하고 클럭 속도가 빨라지며 HBM2가 지원되며 메모리 주소 공간이 넓어집니다.개별 그래픽스 칩셋에는 "HBCC(High Bandwidth Cache Controller)"도 포함되어 있지만 APU에 [45]통합되는 경우에는 포함되어 있지 않습니다.또한 새로운 칩에는 래스터라이제이션 및 렌더 출력 유닛의 개선이 포함될 것으로 기대되고 있습니다.스트림 프로세서는 이전 세대에서 대폭 수정되어 8비트, 16비트 및 32비트 숫자에 대해 패킹된 수학 Rapid Pack Math 기술을 지원합니다.이것에 의해, 저정밀도가 허용 가능한 경우(예를 들면, 1개의 정밀도와 같은 속도로 2개의 반정밀 수치를 처리하는 경우)에는, 큰 퍼포먼스가 향상됩니다.
Nvidia는 [46]Maxwell에 타일 기반 래스터라이제이션과 비닝을 도입했으며, 이것이 Maxwell의 효율성 향상의 큰 이유였습니다.지난 1월 아난드텍은 [47]베가와 함께 선보일 새로운 '드로 스트림 비닝 래스터라이저(DSBR)'로 에너지 효율 최적화와 관련해 베가가 엔비디아를 따라잡을 것으로 예상했다.
또한 새로운 셰이더 단계인 프리미티브 [48][49]셰이더에 대한 지원도 추가되었습니다.원시 셰이더는 보다 유연한 지오메트리 처리를 제공하며 렌더링 파이프라인에서 정점 및 지오메트리 셰이더를 대체합니다.2018년 12월 현재 Primitive 셰이더는 API 변경이 아직 [50]완료되지 않아 사용할 수 없습니다.
베가10과 베가12는 삼성전자가 개발하고 글로벌파운드리스에 라이선스된 14nm 핀펫 공정을 사용한다.베가20은 TSMC가 개발한 7nm FinFET 공정을 사용한다.
칩스
개별 GPU:
- Vega 10 (14 nm Samsung/GlobalFo FinFET 공정) (코드네임[51] 그린란드) (Radeon RX Vega 64), "Radeon RX Vega 56", "Radeon Vega Frontier Edition", "Radeon Pro V340", "Radeon Pro WX FinFET" 및 9100 Radeon에 탑재되어 있습니다.
- Vega 12 (14 nm Samsung/Glo FinFET 공정)는 "Radeon Pro Vega 20" 및 "Radeon Pro Vega 16" 브랜드의 모바일 그래픽[53] 카드에 탑재되어 있습니다.
- Vega 20(7nm TSMC FinFET 프로세스)은 "Radeon Instrent MI50" 및 "Radeon Instrent MI60" 브랜드의 액셀러레이터 카드,[54][55] "Radeon Pro Vega II" 및 "Radeon VII" 브랜드의 그래픽 카드에 있습니다.
APU에 통합:
- Raven[56] Ridge는 VCE 및 UVD를 대체하고 완전한 고정 기능 VP9 디코딩을 지원하는 VCN 1과 함께 제공됩니다.
정밀도 퍼포먼스
베가20을 제외한 모든 GCN 5세대 GPU의 배정밀 부동소수점(FP64) 성능은 16FP32 수준이다.Radeon Instit을 탑재한 Vega 20의 경우 FP32 퍼포먼스의 /입니다.2Radeon VII를 탑재한 Vega 20의 경우 FP32 [57]성능의 /입니다.4모든 GCN 5세대 GPU는 FP32 퍼포먼스의 2배인 반정밀 부동소수점(FP16) 계산을 지원합니다.
「 」를 참조해 주세요.
외부 링크
레퍼런스
- ^ AMD Developer Central (January 31, 2014). "GS-4106 The AMD GCN Architecture – A Crash Course, by Layla Mah". Slideshare.net.
- ^ "AMD Launches World's Fastest Single-GPU Graphics Card – the AMD Radeon HD 7970" (Press release). AMD. December 22, 2011. Archived from the original on January 20, 2015. Retrieved January 20, 2015.
- ^ Gulati, Abheek (November 11, 2019). "An Architectural Deep-Dive into AMD's TeraScale, GCN & RDNA GPU Architectures". Medium. Retrieved December 12, 2021.
{{cite web}}: CS1 maint :url-status (링크) - ^ "AMD community forums". Community.amd.com.
- ^ "LLVM back-end amdgpu". Llvm.org.
- ^ "GCC 9 Release Series Changes, New Features, and Fixes". Retrieved November 13, 2019.
- ^ "AMD GCN Offloading Support". Retrieved November 13, 2019.
- ^ "AMD Boltzmann Initiative – Heterogeneous-compute Interface for Portability (HIP)". November 16, 2015. Archived from the original on January 26, 2016. Retrieved December 8, 2019.
- ^ Smith, Ryan (January 5, 2017). "The AMD Vega GPU Architecture Preview". Anandtech.com. Retrieved July 11, 2017.
- ^ Smith, Ryan. "AMD Dives Deep On Asynchronous Shading". Anandtech.com.
- ^ "Conformant Products". Khronos.org. October 26, 2017.
{{cite web}}: CS1 maint :url-status (링크) - ^ Compute Cores Whitepaper (PDF). AMD. 2014. p. 5.
- ^ a b Smith, Ryan (December 21, 2011). "AMD's Graphics Core Next Preview". Anandtech.com. Retrieved April 18, 2017.
- ^ a b Mantor, Michael; Houston, Mike (June 15, 2011). "AMD Graphics Core Next" (pdf). AMD. p. 40. Retrieved July 15, 2014.
Asynchronous Compute Engine (ACE)
- ^ "White Paper AMD UnifiedVideoDecoder (UVD)" (PDF). June 15, 2012. Retrieved May 20, 2017.
- ^ a b "Not Just A New Architecture, But New Features Too". AnandTech. December 21, 2011. Retrieved July 11, 2014.
- ^ "Kaveri microarchitecture". SemiAccurate. January 15, 2014.
- ^ Airlie, Dave (November 26, 2014). "Merge AMDKFD". freedesktop.org. Retrieved January 21, 2015.
- ^ "/drivers/gpu/drm". Kernel.org.
- ^ "[PATCH 00/83] AMD HSA kernel driver". LKML. July 10, 2014. Retrieved July 11, 2014.
- ^ a b c d e Angelini, Chris (June 29, 2016). "AMD Radeon RX 480 8GB Review". Tom's Hardware. p. 1. Retrieved August 11, 2016.
- ^ "Dissecting the Polaris Architecture" (PDF). 2016. Archived from the original (PDF) on September 20, 2016. Retrieved August 12, 2016.
- ^ Shrout, Ryan (June 29, 2016). "The AMD Radeon RX 480 Review – The Polaris Promise". PC Perspective. p. 2. Archived from the original on October 10, 2016. Retrieved August 12, 2016.
- ^ a b Smith, Ryan (June 29, 2016). "The AMD Radeon RX 480 Preview: Polaris Makes Its Mainstream Mark". AnandTech. p. 3. Retrieved August 11, 2016.
- ^ "AMD Radeon HD 7000 Series to be PCI-Express 3.0 Compliant". TechPowerUp. Retrieved July 21, 2011.
- ^ "AMD Details Next Gen. GPU Architecture". Retrieved August 3, 2011.
- ^ Tony Chen, Jason Greaves, "AMD's Graphics Core Next (GCN) Architecture" (PDF), AMD, retrieved August 13, 2016
{{citation}}: CS1 maint: 작성자 파라미터 사용(링크) - ^ "AMD's Graphics Core Next Preview: AMD's New GPU, Architected For Compute". AnandTech. December 21, 2011. Retrieved July 15, 2014.
AMD's new Asynchronous Compute Engines serve as the command processors for compute operations on GCN. The principal purpose of ACEs will be to accept work and to dispatch it off to the CUs for processing.
- ^ "Managing Idle Power: Introducing ZeroCore Power". AnandTech.com. December 22, 2011. Retrieved April 29, 2015.
- ^ "AMD's Kaveri A10-7850K tested". AnandTech. January 14, 2014. Retrieved July 7, 2014.
- ^ "AMD Radeon R9-290X". November 21, 2013.
- ^ "Carrizo Overview" (PNG). Images.anandtech.com. Retrieved July 20, 2018.
- ^ "Add DCC Support". Freedesktop.org. October 11, 2015.
- ^ Smith, Ryan (September 10, 2014). "AMD Radeon R9 285 Review". Anandtech.com. Retrieved March 13, 2017.
- ^ a b Cutress, Ian (June 1, 2016). "AMD Announces 7th Generation APU". Anandtech.com. Retrieved June 1, 2016.
- ^ "Radeon Feature Matrix: GCA".
- ^ "Radeon Technologies Group – January 2016 – AMD Polaris Architecture". Guru3d.com.
- ^ a b Smith, Ryan (January 5, 2017). "The AMD Vega Architecture Teaser: Higher IPC, Tiling, & More, coming in H1'2017". Anandtech.com. Retrieved January 10, 2017.
- ^ WhyCry (March 24, 2016). "AMD confirms Polaris 10 is Ellesmere and Polaris 11 is Baffin". VideoCardz. Retrieved April 8, 2016.
- ^ "Fast vollständige Hardware-Daten zu AMDs Radeon RX 500 Serie geleakt". www.3dcenter.org.
- ^ "AMD Polaris 23". TechPowerUp. Retrieved May 12, 2022.
- ^ Oh, Nate (November 15, 2018). "The AMD Radeon RX 590 Review, feat. XFX & PowerColor: Polaris Returns (Again)". anandtech.com. Retrieved November 24, 2018.
- ^ Kampman, Jeff (January 5, 2017). "The curtain comes up on AMD's Vega architecture". TechReport.com. Retrieved January 10, 2017.
- ^ Shrout, Ryan (January 5, 2017). "AMD Vega GPU Architecture Preview: Redesigned Memory Architecture". PC Perspective. Retrieved January 10, 2017.
- ^ Kampman, Jeff (October 26, 2017). "AMD's Ryzen 7 2700U and Ryzen 5 2500U APUs revealed". Techreport.com. Retrieved October 26, 2017.
- ^ Raevenlord (March 1, 2017). "On NVIDIA's Tile-Based Rendering". techPowerUp.
- ^ "Vega Teaser: Draw Stream Binning Rasterizer". Anandtech.com.
- ^ "Radeon RX Vega Revealed: AMD promises 4K gaming performance for $499 – Trusted Reviews". Trustedreviews.com. July 31, 2017.
- ^ "The curtain comes up on AMD's Vega architecture". Techreport.com.
- ^ Kampman, Jeff (January 23, 2018). "Radeon RX Vega primitive shaders will need API support". Techreport.com. Retrieved December 29, 2018.
- ^ "ROCm-OpenCL-Runtime/libUtils.cpp at master · RadeonOpenCompute/ROCm-OpenCL-Runtime". github.com. May 3, 2017. Retrieved November 10, 2018.
- ^ "The AMD Radeon RX Vega 64 & RX Vega 56 Review: Vega Burning Bright". Anandtech.com. August 14, 2017. Retrieved November 16, 2017.
- ^ "AMD's Vega Mobile Lives: Vega Pro 20 & 16 in Updated MacBook Pros In November". Anandtech.com. October 30, 2018. Retrieved November 10, 2018.
- ^ "AMD Announces Radeon Instinct MI60 & MI50 Accelerators: Powered By 7nm Vega". Anandtech.com. November 6, 2018. Retrieved November 10, 2018.
- ^ "AMD Unveils World's First 7nm Gaming GPU – Delivering Exceptional Performance and Incredible Experiences for Gamers, Creators and Enthusiasts" (Press release). Las Vegas, Nevada: AMD. January 9, 2019. Retrieved January 12, 2019.
- ^ Ferreira, Bruno (May 16, 2017). "Ryzen Mobile APUs are coming to a laptop near you". Tech Report. Retrieved May 16, 2017.
- ^ "AMD Unveils World's First 7nm Datacenter GPUs – Powering the Next Era of Artificial Intelligence, Cloud Computing and High Performance Computing (HPC) AMD". AMD.com (Press release). November 6, 2018. Retrieved November 10, 2018.



{kind=link}