레터 빈도
Letter frequency| 편지 | 영어의[1] 상대 주파수 | |||
|---|---|---|---|---|
| 텍스트 | 사전 | |||
| A | 8.2% | 7.8% | ||
| B | 1.5% | 2% | ||
| C | 2.8% | 4% | ||
| D | 4.3% | 3.8% | ||
| E | 13% | 11% | ||
| F | 2.2% | 1.4% | ||
| G | 2% | 3% | ||
| H | 6.1% | 2.3% | ||
| I | 7% | 8.6% | ||
| J | 0.15% | 0.21% | ||
| K | 0.77% | 0.97% | ||
| L | 4% | 5.3% | ||
| M | 2.4% | 2.7% | ||
| N | 6.7% | 7.2% | ||
| O | 7.5% | 6.1% | ||
| P | 1.9% | 2.8% | ||
| Q | 0.095% | 0.19% | ||
| R | 6% | 7.3% | ||
| S | 6.3% | 8.7% | ||
| T | 9.1% | 6.7% | ||
| U | 2.8% | 3.3% | ||
| V | 0.98% | 1% | ||
| W | 2.4% | 0.91% | ||
| X | 0.15% | 0.27% | ||
| Y | 2% | 1.6% | ||
| Z | 0.074% | 0.44% | ||
문자 빈도는 문자 언어에서 알파벳의 문자가 평균적으로 나타나는 횟수입니다.문자 빈도 분석은 암호를 해독하는 방법을 공식적으로 개발한 아랍 수학자 알 킨디(801–873년)로 거슬러 올라간다.문자 빈도 분석은 유럽에서 1450년 가동 활자의 개발과 함께 중요해졌다. 여기서 각 문자 형식에 필요한 활자의 양을 추정해야 한다.언어학자들은 문자 빈도 분석을 언어 식별을 위한 기본적인 기술로 사용합니다. 여기서 미지의 문자 체계가 알파벳인지, 음절 문자인지, 또는 표의 문자인지를 나타내는 데 특히 효과적입니다.
암호문자와 Hangman, Scrabble, Wordle[2] 및 TV 게임 쇼 Wheel of Fortune을 포함한 여러 단어 퍼즐 게임에서 문자 빈도와 빈도 분석은 기본적인 역할을 합니다.암호문자를 풀기 위해 영어 문자 빈도를 적용하는 것에 대한 고전 문학에서 가장 초기의 기술 중 하나는 에드거 앨런 포의 유명한 이야기인 골드버그에서 발견되는데, 여기서 이 방법은 [3]키드 선장이 숨겨놓은 보물의 위치를 알려 주는 메시지를 해독하는 데 성공적으로 적용된다.
Herbert S. Zim은 그의 고전 암호학 입문 텍스트 "Codes and Secret Writing"에서 영어 문자 주파수 시퀀스를 "ETAON RISHD LFCMU GYPWB VKJXZQ"로 지정합니다.이것은 ER의 가장 일반적인 문자 쌍인 "THHE AN RE"입니다.계산 방법이 다르면 순서가 약간 다를 수 있습니다.
또한 문자 빈도는 일부 키보드 레이아웃 설계에 큰 영향을 미칩니다.가장 빈번한 글자는 Blickensderfer 타자기의 맨 아래 행과 Dvorak 자판 배열의 맨 아래 행에 있습니다.
배경

텍스트의 문자의 빈도는 암호해석에 사용하기 위해 연구되어 왔으며, 특히 이 방법을 공식적으로 개발한 아랍 수학자 알 킨디(801년–873년)로 거슬러 올라간다(이 기술에 의해 깨질 수 있는 암호는 적어도 율리우스 시저에 의해 발명된 시저 암호로 거슬러 올라가기 때문에, 이 방법은 e가 될 수 있었다).xplored in the classical time).유럽에서 문자 빈도 분석은 서기 1450년에 가동 활자가 개발되면서 더욱 중요해졌다. 여기서 인쇄술자의 활자 케이스에서 글자 칸 크기 변화로 증명되었듯이 각 문자 형식에 필요한 활자의 양을 추정해야 한다.
모든 작가가 조금씩 다르게 쓰기 때문에 정확한 문자 빈도 분포는 특정 언어의 기초가 되지 않습니다.그러나 대부분의 언어는 긴 텍스트에서 강하게 나타나는 특징적인 분포를 가지고 있다.심지어 고대 영어에서 현대 영어(상호 이해 불가능한 것으로 간주됨)로 극단적인 언어 변화도 관련 서한 빈도에서 강한 경향을 보인다: 가장 빈번한 것부터 가장 빈도가 낮은 것까지 성서 구절의 작은 샘플에 대해 현대 영어의 eothard sin luymw fgbp kvjxz와 비교하여 고대 영어의 sorhm tgllwu éfgu wulwu cfwuwuwuwuwulllllllyllllllððllllðððððlllððððððððððððððh [5]공유되지 않은 문자 형태에 관한 가장 극단적인 차이.
영어용 라이노타이프 기계는 수동 컴포넌트의 경험과 관습에 따라 가장 일반적인 것부터 가장 일반적인 것까지 문자 순서를 etaoin shrdlu cmfwyp vbgkjq xz로 가정했다.프랑스어는 elaoin sdrétu cmfhyp vbgwqj xz였다.
Morse에서 알파벳을 같은 시간 동안 전송해야 하는 문자 그룹으로 정렬하고 이러한 그룹을 순서대로 정렬하면 san hurdm wgvlfbk opxcz jyq가 [a]생성됩니다.편지 빈도는 머레이 코드와 같은 다른 전신 시스템에서 사용되었습니다.
Huffman 코딩과 같은 최신 데이터 압축 기술에도 유사한 아이디어가 사용됩니다.
글자 빈도는 단어 빈도와 마찬가지로 작가와 제목에 따라 달라지는 경향이 있습니다.X-레이에 대한 에세이를 쓸 때는 X-레이를 자주 사용해야 하며, 카타르에서 얼룩말을 치료하기 위해 X-레이를 사용한다면 에세이는 독특한 글자 빈도를 갖게 될 것이다.작가마다 글자를 사용하는 습관이 있다.예를 들어 헤밍웨이의 작문 스타일은 포크너의 작문 스타일과는 확연히 다르다.글자, 빅램, 트리그램, 단어 빈도, 단어 길이, 문장 길이는 특정 저자에 대해 계산될 수 있으며, 문체의 차이가 크지 않은 저자에 대해서도 텍스트의 저자를 증명하거나 반증하는 데 사용될 수 있다.
정확한 평균 문자 빈도는 많은 양의 대표 텍스트를 분석해야만 수집할 수 있습니다.현대 컴퓨팅과 대형 텍스트 코퍼스의 컬렉션을 이용할 수 있게 되면서 이러한 계산은 쉽게 이루어집니다.예는 다양한 출처(언론 보도, 종교 텍스트, 과학 텍스트 및 일반 픽션)에서 도출할 수 있으며, 특히 'h'와 'i'의 위치가 일반화되어 일반 픽션의 경우 차이가 있다.
또한, 언어의 다른 방언들도 글자의 빈도에 영향을 미친다는 것을 주목한다.예를 들어, 미국의 한 작가는 같은 주제에 대해 글을 쓰는 영국 작가보다 문자 'z'가 더 흔한 무언가를 만들 것이다: "analyze", "apologize", "recognize"와 같은 단어들은 미국 영어에서는 그 편지를 포함하고 있는 반면, 같은 단어들은 "analyze", "apologize"와 "regenize"로 철자된다.이것은 영어에서 영국인들이 [6]거의 사용하지 않는 문자이기 때문에 알파벳 'z'의 빈도에 큰 영향을 미칠 것이다.
"상위 12개" 문자는 전체 사용량의 약 80%를 차지합니다."상위 8개" 문자는 전체 사용량의 약 65%를 차지합니다.등급의 함수로서의 문자 빈도는 여러 등급 함수로 잘 적합할 수 있으며, 2-파라미터 Cocho/Beta 등급 함수가 [7]가장 좋습니다.조절 가능한 자유 매개변수가 없는 또 다른 순위 함수 역시 문자 빈도 분포에 상당히[8] 잘 맞습니다(단백질 배열에서 아미노산 빈도를 맞추기 위해 동일한 기능이 사용되었습니다).[9]VIC 암호 또는 스트래들링 체커보드에 기반한 다른 암호를 사용하는 스파이는 일반적으로 상위 8개의 문자를 기억하기 위해 "a sin to err"(두 번째 "r"[10][11] 드롭) 또는 "at at sir"[12]와 같은 니모닉을 사용합니다.
영어 문자의 상대 빈도

문자 빈도를 계산하는 방법에는 세 가지가 있으며, 일반 문자에 대한 차트는 매우 다릅니다.아래 표에 사용된 첫 번째 방법은 사전의 루트 워드에서 문자 빈도를 계산하는 것입니다.두 번째는 "추상", "추상", "추상"과 같은 모든 단어 변형을 셀 때 "추상"의 어근뿐만 아니라 "추상"도 포함합니다.이 시스템은 인터넷에서 가장 많이 사용되는 영어 단어 목록에서 글자를 셀 때처럼 s와 같은 글자가 훨씬 더 자주 나타나게 한다.마지막 변형은 실제 텍스트에서 사용되는 빈도에 따라 글자를 세는 것으로, "th", "then", "both", "this" 등과 같은 일반적인 단어가 자주 사용되기 때문에 'th'와 같은 특정 글자 조합이 더 일반적이게 된다.이와 같은 절대 사용 빈도 척도는 구식 인쇄기로 키보드 레이아웃이나 문자 빈도를 작성할 때 사용됩니다.
단어 사용 빈도를 무시하고 간결한 옥스퍼드 사전의 항목을 분석하면 "EARIOTNSLCUDMHGBFYWKXZJQ"[13]의 순서가 지정됩니다.
아래의 문자 빈도 표는 로버트 르완드의 암호 [14]수학을 인용한 파벨 미치카의 웹사이트에서 가져온 것입니다.
Lewand에 따르면, 외관상 가장 일반적인 것부터 가장 일반적인 것까지 배열된 문자는 etaoinshrdcumwgypbvkjxcz입니다.르완드의 순서는 4만 [15]단어를 측정해 표를 만든 코넬대 수학탐험기 프로젝트와 조금 다르다.
영어의 경우 공백이 맨 [16]위 문자 e보다 약간 더 잦고 알파벳이 아닌 문자(자리, 구두점 등)가 t와 [17]a 사이의 네 번째 자리(이미 공백을 포함)를 차지한다.
영어 단어 첫 글자의 상대 빈도
| 편지 | 영어[citation needed] 단어의 첫 글자로서의 상대 빈도 | |||
|---|---|---|---|---|
| 텍스트 | 사전 | |||
| A | 11.7% | 5.7% | ||
| B | 4.4% | 6% | ||
| C | 5.2% | 9.4% | ||
| D | 3.2% | 6.1% | ||
| E | 2.8% | 3.9% | ||
| F | 4% | 4.1% | ||
| G | 1.6% | 3.3% | ||
| H | 4.2% | 3.7% | ||
| I | 7.3% | 3.9% | ||
| J | 0.51% | 1.1% | ||
| K | 0.86% | 1% | ||
| L | 2.4% | 3.1% | ||
| M | 3.8% | 5.6% | ||
| N | 2.3% | 2.2% | ||
| O | 7.6% | 2.5% | ||
| P | 4.3% | 7.7% | ||
| Q | 0.22% | 0.49% | ||
| R | 2.8% | 6% | ||
| S | 6.7% | 11% | ||
| T | 16% | 5% | ||
| U | 1.2% | 2.9% | ||
| V | 0.82% | 1.5% | ||
| W | 5.5% | 2.7% | ||
| X | 0.045% | 0.05% | ||
| Y | 0.76% | 0.36% | ||
| Z | 0.045% | 0.24% | ||
단어 또는 이름의 첫 글자의 빈도는 실제 파일 및 [18]인덱스에서 공간을 미리 할당할 때 유용합니다.26개의 파일 캐비닛 드로어가 있는 경우, 1개의 드로어를 알파벳의 한 문자에 1:1로 할당하는 것이 아니라, 같은 드로어에 여러 개의 저주파 문자를 할당하여(종종종 1개의 드로어를 VWXYZ라고 부릅니다), 가장 빈번한 첫 글자('S', 'A', 'C')를 여러 개의 문자로 분할하는 것이 편리합니다.드로어(종종 6 드로어 Aa-An, Ao-Az, Ca-Cj, Ck-Cz, Sa-Si, Sj-Sz).일부 백과사전과 같은 여러 권의 저작물에도 동일한 시스템이 사용됩니다.일부 라이브러리에서는 동일한 주파수 코드에 이름을 매핑하는 또 다른 커터 번호가 사용됩니다.
전체 문자 분포와 단어 머리글자 분포 모두 Zipf 분포와 거의 일치하며 Yule 분포와 더욱 [19]밀접하게 일치합니다.
종종 각 기준에서 첫 번째 자리의 빈도 분포는 일련의 숫자 데이터에 있는 모든 자리의 전체 빈도와 상당히 다르다. 자세한 내용은 Benford의 법칙을 참조하십시오.
구글 북스 데이터에 대한 피터 노빅의 분석은 무엇보다도 영어 [20]단어의 첫 글자의 빈도를 알아냈다.
2012년 6월, 영어의 모든 단어를 정확히 한 번 포함하는 텍스트 문서를 사용한 분석 결과, 영어 단어의 가장 일반적인 시작 문자로 'S'가 꼽혔으며, 그 다음으로 'P', 'C',[21] 'A'가 그 뒤를 이었다.
다른 언어의 상대적인 문자 빈도
이 섹션에는 텍스트를 검증하지 않는 부적절하거나 잘못 해석된 인용문이 포함되어 있을 수 있습니다.(2014년 7월 (이 및 ) |
| 편지 | 영어[필요한 건] | 프랑스어[22] | 독일의[23] | 스페인어[24] | 포르투갈어[25] | 에스페란토[26] | 이탈리아의[27] | 터키어[28] | 스웨덴어[29] | 폴란드의[30] | 네덜란드어[31] | 덴마크어[32] | 아이슬란드어[33] | 핀란드어[34] | 체코어[필요한 건] |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| a | 8.167% | 7.636% | 6.516% | 11.525% | 14.634% | 12.117% | 11.745% | 11.920% | 9.383% | 8.910% | 7.486% | 6.025% | 10.110% | 12.217% | 8.421% |
| b | 1.492% | 0.901% | 1.886% | 2.215% | 1.043% | 0.980% | 0.927% | 2.844% | 1.535% | 1.470% | 1.584% | 2.000% | 1.043% | 0.281% | 0.822% |
| c | 2.782% | 3.260% | 2.732% | 4.019% | 3.882% | 0.776% | 4.501% | 0.963% | 1.486% | 3.960% | 1.242% | 0.565% | ~0% | 0.281% | 0.740% |
| d | 4.253% | 3.669% | 5.076% | 5.010% | 4.992% | 3.044% | 3.736% | 4.706% | 4.702% | 3.250% | 5.933% | 5.858% | 1.575% | 1.043% | 3.475% |
| e | 12.702% | 14.715% | 16.396% | 12.181% | 12.570% | 8.995% | 11.792% | 8.912% | 10.149% | 7.660% | 18.91% | 15.453% | 6.418% | 7.968% | 7.562% |
| f | 2.228% | 1.066% | 1.656% | 0.692% | 1.023% | 1.037% | 1.153% | 0.461% | 2.027% | 0.300% | 0.805% | 2.406% | 3.013% | 0.194% | 0.084% |
| g | 2.015% | 0.866% | 3.009% | 1.768% | 1.303% | 1.171% | 1.644% | 1.253% | 2.862% | 1.420% | 3.403% | 4.077% | 4.241% | 0.392% | 0.092% |
| h | 6.094% | 0.737% | 4.577% | 0.703% | 0.781% | 0.384% | 0.636% | 1.212% | 2.090% | 1.080% | 2.380% | 1.621% | 1.871% | 1.851% | 1.356% |
| i | 6.966% | 7.529% | 6.550% | 6.247% | 6.186% | 10.012% | 10.143% | 8.600%* | 5.817% | 8.210% | 6.499% | 6.000% | 7.578% | 10.817% | 6.073% |
| j | 0.153% | 0.613% | 0.268% | 0.493% | 0.397% | 3.501% | 0.011% | 0.034% | 0.614% | 2.280% | 1.46% | 0.730% | 1.144% | 2.042% | 1.433% |
| k | 0.772% | 0.074% | 1.417% | 0.011% | 0.015% | 4.163% | 0.009% | 4.683% | 3.140% | 3.510% | 2.248% | 3.395% | 3.314% | 4.973% | 2.894% |
| l | 4.025% | 5.456% | 3.437% | 4.967% | 2.779% | 6.104% | 6.510% | 5.922% | 5.275% | 2.100% | 3.568% | 5.229% | 4.532% | 5.761% | 3.802% |
| m | 2.406% | 2.968% | 2.534% | 3.157% | 4.738% | 2.994% | 2.512% | 3.752% | 3.471% | 2.800% | 2.213% | 3.237% | 4.041% | 3.202% | 2.446% |
| n | 6.749% | 7.095% | 9.776% | 6.712% | 4.446% | 7.955% | 6.883% | 7.487% | 8.542% | 5.520% | 10.032% | 7.240% | 7.711% | 8.826% | 6.468% |
| o | 7.507% | 5.796% | 2.594% | 8.683% | 9.735% | 8.779% | 9.832% | 2.476% | 4.482% | 7.750% | 6.063% | 4.636% | 2.166% | 5.614% | 6.695% |
| p | 1.929% | 2.521% | 0.670% | 2.510% | 2.523% | 2.755% | 3.056% | 0.886% | 1.839% | 3.130% | 1.57% | 1.756% | 0.789% | 1.842% | 1.906% |
| q | 0.095% | 1.362% | 0.018% | 0.877% | 1.204% | 0 | 0.505% | 0 | 0.020% | 0.140% | 0.009% | 0.007% | 0 | 0.013% | 0.001% |
| r | 5.987% | 6.693% | 7.003% | 6.871% | 6.530% | 5.914% | 6.367% | 6.722% | 8.431% | 4.690% | 6.411% | 8.956% | 8.581% | 2.872% | 4.799% |
| s | 6.327% | 7.948% | 7.270% | 7.977% | 6.805% | 6.092% | 4.981% | 3.014% | 6.590% | 4.320% | 3.73% | 5.805% | 5.630% | 7.862% | 5.212% |
| t | 9.056% | 7.244% | 6.154% | 4.632% | 4.336% | 5.276% | 5.623% | 3.314% | 7.691% | 3.980% | 6.79% | 6.862% | 4.953% | 8.750% | 5.727% |
| u | 2.758% | 6.311% | 4.166% | 2.927% | 3.639% | 3.183% | 3.011% | 3.235% | 1.919% | 2.500% | 1.99% | 1.979% | 4.562% | 5.008% | 2.160% |
| v | 0.978% | 1.838% | 0.846% | 1.138% | 1.575% | 1.904% | 2.097% | 0.959% | 2.415% | 0.040% | 2.85% | 2.332% | 2.437% | 2.250% | 5.344% |
| w | 2.360% | 0.049% | 1.921% | 0.017% | 0.037% | 0 | 0.033% | 0 | 0.142% | 4.650% | 1.52% | 0.069% | 0 | 0.094% | 0.016% |
| x | 0.150% | 0.427% | 0.034% | 0.215% | 0.253% | 0 | 0.003% | 0 | 0.159% | 0.020% | 0.036% | 0.028% | 0.046% | 0.031% | 0.027% |
| y | 1.974% | 0.128% | 0.039% | 1.008% | 0.006% | 0 | 0.020% | 3.336% | 0.708% | 3.760% | 0.035% | 0.698% | 0.900% | 1.745% | 1.043% |
| z | 0.074% | 0.326% | 1.134% | 0.467% | 0.470% | 0.494% | 1.181% | 1.500% | 0.070% | 5.640% | 1.39% | 0.034% | 0 | 0.051% | 1.599% |
| 아 | 0%[citation needed]까지 | 0.486% | 0 | ~0% | 0.072% | 0 | 0.635% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ★ | ~0% | 0.051% | 0 | 0 | 0.562% | 0 | ~0% | ~0% | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 아 | ~0% | 0 | 0 | 0.502% | 0.118% | 0 | 0 | 0 | 0 | ~0% | 0 | 0 | 1.799% | 0 | 0.867% |
| å | ~0% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1.338% | 0 | 0 | 1.190% | ~0% | 0.003% | 0 |
| ä | ~0% | 0 | 0.578% | 0 | 0 | 0 | 0 | 0 | 1.797% | 0 | 0 | 0 | 0 | 3.577% | 0 |
| ã | 0 | 0 | 0 | 0 | 0.733% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ą | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.990% | 0 | 0 | 0 | 0 | 0 |
| æ | 0%[citation needed]까지 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.872% | 0.867% | 0 | 0 |
| œ | ~0% | 0.018% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 츠 | ~0% | 0.085% | 0 | ~0% | 0.530% | 0 | 0 | 1.156% | 0 | 0 | 0 | 0 | ~0% | 0 | 0 |
| ĉ | 0 | 0 | 0 | 0 | 0 | 0.657% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ć | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.400% | 0 | 0 | 0 | 0 | 0 |
| č | ~0% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ~0% | 0 | 0 | 0 | 0 | 0.462% |
| ď | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.015% |
| ð | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 4.393% | 0 | 0 |
| è | 0%[citation needed]까지 | 0.271% | 0 | ~0% | 0 | 0 | 0.263% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 에 | 0%[citation needed]까지 | 1.504% | 0 | 0.433% | 0.337% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.647% | 0 | 0.633% |
| ê | 0 | 0.218% | 0 | 0 | 0.450% | 0 | ~0% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ë | 0%[citation needed]까지 | 0.008% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ę | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1.110% | 0 | 0 | 0 | 0 | 0 |
| ě | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1.222% |
| ĝ | 0 | 0 | 0 | 0 | 0 | 0.691% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ğ | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1.125% | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ĥ | 0 | 0 | 0 | 0 | 0 | 0.022% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| î | 0 | 0.045% | 0 | 0 | 0 | 0 | ~0% | ~0% | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ì | 0 | 0 | 0 | 0 | 0 | 0 | (0.030%) | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ii | 0[citation needed] | 0 | 0 | 0.725% | 0.132% | 0 | 0.030% | 0 | 0 | 0 | 0 | 0 | 1.570% | 0 | 1.643% |
| ï | 0%[citation needed]까지 | 0.005% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ı | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 5.114%* | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ĵ | 0 | 0 | 0 | 0 | 0 | 0.055% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ł | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1.820% | 0 | 0 | 0 | 0 | 0 |
| ľ | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ~0% |
| ñ | 0%[citation needed]까지 | 0 | 0 | 0.311% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ń | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.200% | 0 | 0 | 0 | 0 | 0 |
| ň | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.007% |
| ò | 0 | 0 | 0 | 0 | 0 | 0 | 0.002% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ö | ~0% | 0 | 0.443% | 0 | 0 | 0 | 0 | 0.777% | 1.305% | 0 | 0 | 0 | 0.777% | 0.444% | 0 |
| o | ~0% | 0.023% | 0 | 0 | 0.635% | 0 | ~0% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| o | 0[citation needed] | 0 | 0 | 0.827% | 0.296% | 0 | ~0% | 0 | 0 | 0.850% | 0 | 0 | 0.994% | 0 | 0.024% |
| õ | 0[citation needed] | 0 | 0 | 0 | 0.040% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ø | ~0% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.939% | 0 | 0 | 0 |
| ř | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.380% |
| ŝ | 0 | 0 | 0 | 0 | 0 | 0.385% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ş | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1.780% | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ś | 0[citation needed] | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.660% | 0 | 0 | 0 | 0 | 0 |
| š | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ~0% | 0 | 0 | 0 | ~0% | 0.688% |
| ß | 0 | 0 | 0.307% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ť | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.006% |
| þ | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1.455% | 0 | 0 |
| ù | 0 | 0.058% | 0 | 0 | 0 | 0 | (0.166%) | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| u | 0[citation needed] | 0 | 0 | 0.168% | 0.207% | 0 | 0.166% | 0 | 0 | 0 | 0 | 0 | 0.613% | 0 | 0.045% |
| û | ~0% | 0.060% | 0 | 0 | 0 | 0 | ~0% | ~0% | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ŭ | 0 | 0 | 0 | 0 | 0 | 0.520% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ü | ~0% | 0 | 0.995% | 0.012% | 0.026% | 0 | 0 | 1.854% | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ů | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.204% |
| ý | 0 | 0 | 0 | ~0% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.228% | 0 | 0.995% |
| ź | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.060% | 0 | 0 | 0 | 0 | 0 |
| ż | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.830% | 0 | 0 | 0 | 0 | 0 |
| 쯔 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ~0% | 0.721% |
*'I' 및 '점 없는 I' 참조.
아래 그림은 일부 언어에서 가장 일반적인 26개의 라틴 문자의 빈도 분포를 보여줍니다.이 언어들은 모두 비슷한 25자 이상의 알파벳을 사용합니다.
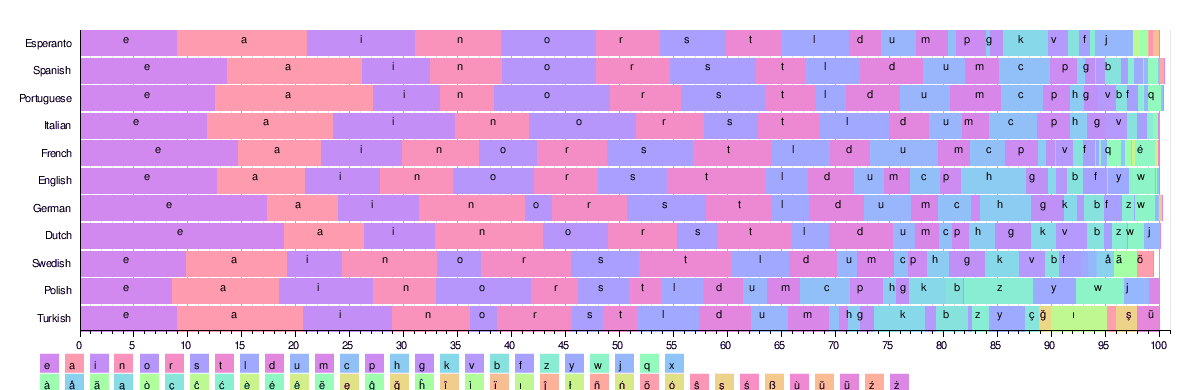
이러한 표를 바탕으로 각 언어의 'etaoin shrdlu' 등가 결과는 다음과 같습니다.
- 프랑스어: 'eSAit nruol'; (인도유럽어:이탤릭체; 전통적으로 'esartinulop'은 발음하기[35] 쉽기 때문에 사용됩니다.)
- 스페인어: 'eaosr nidlt'; (인도유럽어:이탤릭체)
- 포르투갈어: 'aeosr idmnt'(인도유럽어:이탤릭체)
- 이탈리아어: 'eaion lrtsc'; (인도유럽어:이탤릭체)
- 에스페란토: 'aieon lsrtk' (인공언어 - 인도유럽어, 로망스어, 게르만어의 영향을 받은 어휘)
- 독일어: 'ensri atdhu'; (인도유럽어:독일어)
- 스웨덴어: 'eanrt sildo'; (인도유럽어:독일어)
- 터키어: 'aeinr lükdm'; (터키어)
- 네덜란드어: 'enati rodsl'; (인도유럽어:독일어)[31]
- 폴란드어: 'aioez nrwst'; (인도유럽어: Balto-Slavic)
- 덴마크어: 'ernta idslo'; (인도유럽어:독일어)
- 아이슬란드어: 'arnie stuld'; (인도유럽어:독일어)
- 핀란드어: '인테 슬로크'; (우랄어:핀어)
- 체코어: 'aeoni tvsrl'; (인도유럽어: Balto-Slavic)
「 」를 참조해 주세요.
설명 메모
레퍼런스
- ^ Mička, Pavel. "Letter frequency (English)". Algoritmy.net. Archived from the original on 4 March 2021. Retrieved 14 June 2022.
Source is Leland, Robert. Cryptological mathematics. [s.l.] : The Mathematical Association of America, 2000. 199 p. ISBN 0-88385-719-7
- ^ Guinness, Harry. "The Best Starting Words to Win at Wordle". Wired. ISSN 1059-1028. Retrieved 2022-02-12.
- ^ Poe, Edgar Allan. "The works of Edgar Allan Poe in five volumes". Project Gutenberg.
- ^ Zim, Herbert Spencer (1961). Codes & Secret Writing: Authorized Abridgement. Scholastic Book Services. OCLC 317853773.
- ^ Moreno, Marsha Lynn (Spring 2005). "Frequency Analysis in Light of Language Innovation" (PDF). Math. University of California – San Diego. Retrieved 19 February 2015.
- ^ "British and American spelling - Oxford Dictionaries". Oxford Dictionaries - English. Retrieved 18 April 2018.
- ^ Li, Wentian; Miramontes, Pedro (2011). "Fitting ranked English and Spanish letter frequency distribution in US and Mexican presidential speeches". Journal of Quantitative Linguistics. 18 (4): 359. arXiv:1103.2950. doi:10.1080/09296174.2011.608606. S2CID 1716455.
- ^ Gusein-Zade, S.M. (1988). "Frequency distribution of letters in the Russian language". Probl. Peredachi Inf. 24 (4): 102–107.
- ^ Gamow, George; Ycas, Martynas (1955). "Statistical correlation of protein and ribonucleic acid composition". Proc. Natl. Acad. Sci. 41 (12): 1011–1019. Bibcode:1955PNAS...41.1011G. doi:10.1073/pnas.41.12.1011. PMC 528190. PMID 16589789.
- ^ Bauer, Friedrich L. (2006). Decrypted Secrets: Methods and maxims of cryptology. p. 57. ISBN 9783540481218 – via Google Books.
- ^ Goebel, Greg (2009). The Rise Of Field Ciphers: straddling checkerboard ciphers.
- ^ Rijmenants, Dirk. "One-time Pad".
- ^ "What is the frequency of the letters of the alphabet in English?". Oxford Dictionary. Oxford University Press. Retrieved 29 December 2012.
- ^ Mička, Pavel. "Letter frequency (English)". Algoritmy.net.
- ^ "Frequency Table". cornell.edu. Retrieved 2021-01-24.
{{cite web}}: CS1 maint :url-status (링크) - ^ "Statistical Distributions of English Text". data-compression.com. Archived from the original on 2017-09-18.
- ^ Lee, E. Stewart. "Essays about Computer Security" (PDF). University of Cambridge Computer Laboratory. p. 181.
- ^ Ohlman, Herbert Marvin (1959). Subject-Word Letter Frequencies with Applications to Superimposed Coding. Proceedings of the International Conference on Scientific Information. doi:10.17226/10866. ISBN 978-0-309-57421-1.
- ^ Pande, Hemlata; Dhami, H.S. "Mathematical Modelling of Occurrence of Letters and Word's Initials in Texts of Hindi Language" (PDF). JTL. 16.
- ^ "English Letter Frequency Counts: Mayzner revisited or ETAOIN SRHLDCU". norvig.com. Retrieved 18 April 2018.
- ^ "Which English Letter Has Maximum Words". June 25, 2012.
- ^ "Corpus de Thomas Tempé". Archived from the original on 30 September 2007. Retrieved 15 June 2007.
- ^ Beutelspacher, Albrecht (2005). Kryptologie (7 ed.). Wiesbaden: Vieweg. p. 10. ISBN 3-8348-0014-7.
- ^ Pratt, Fletcher (1942). Secret and Urgent: The story of codes and ciphers. Garden City, NY: Blue Ribbon Books. pp. 254–5. OCLC 795065.
- ^ "Frequência da ocorrência de letras no Português". Archived from the original on 3 August 2009. Retrieved 16 June 2009.
- ^ "La Oftecoj de la Esperantaj Literoj". Retrieved 14 September 2007.
- ^ Singh, Simon; Galli, Stefano (1999). Codici e Segreti (in Italian). Milano: Rizzoli. ISBN 978-8-817-86213-4. OCLC 535461359.
- ^ Serengil, Sefik Ilkin; Akin, Murat (20–22 February 2011). Attacking Turkish Texts Encrypted by Homophonic Cipher (PDF). Proceedings of the 10th WSEAS International Conference on Electronics, Hardware, Wireless and Optical Communications. Cambridge, UK. pp. 123–126.
- ^ "Practical Cryptography". Retrieved 30 October 2013.
- ^ "Frekwencja liter w polskich tekstach - Poradnia językowa PWN".
- ^ a b "Letterfrequenties". Genootschap OnzeTaal. Retrieved 17 May 2009.
- ^ "Danish letter frequencies". Practical Cryptography. Retrieved 24 October 2013.
- ^ "Icelandic letter frequencies". Practical Cryptography. Retrieved 24 October 2013.
- ^ "Finnish letter frequencies". Practical Cryptography. Retrieved 24 October 2013.
- ^ Perec, Georges; 알파벳; Editions Galilé, 1976
외부 링크
- Lewand, Robert Edward. "Cryptographical Mathematics". pages.central.edu. Archived from the original on 2007-04-02.
- "Some examples of letter frequency rankings in some common languages". www.bckelk.org.uk.
- "JavaScript Heatmap Visualization showing letter frequencies of texts on different keyboard layouts". www.patrick-wied.at.
- Norvig, Peter. "An updated version of Mayzner's work using Google books Ngrams data set". norvig.com.
- 레터 빈도: simia.그물
유용한 표
단어 길이 3 ~7 글자의 단어 길이 및 문자 위치 조합을 고려한 20,000개의 단어를 기반으로 한 단일 문자, 디그램, 트리그램, 테트라그램 및 펜타그램 주파수에 대한 유용한 표:
- Mayzner, M.S.; Tresselt, M.E.; Wolin, B.R. (1965). "Tables of single-letter and digram frequency counts for various word-length and letter-position combinations". Psychonomic Monograph Supplements. 1 (2): 13–32. OCLC 639975358.
- Mayzner, M.S.; Tresselt, M.E.; Wolin, B.R. (1965). "Tables of trigram frequency counts for various word-length and letter-position combinations". Psychonomic Monograph Supplements. 1 (3): 33–78.
- Mayzner, M.S.; Tresselt, M.E.; Wolin, B.R. (1965). "Tables of tetragram frequency counts for various word-length and letter-position combinations". Psychonomic Monograph Supplements. 1 (4): 79–143.
- Mayzner, M.S.; Tresselt, M.E.; Wolin, B.R. (1965). "Tables of pentagram frequency counts for various word-length and letter-position combinations". Psychonomic Monograph Supplements. 1 (5): 144–190.

