R*트리
R*-tree| R*트리 | |||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 발명된 | 1990 | ||||||||||||||||
| 발명자 | 노르베르트 베크만, 한스 피터 크리겔, 랄프 슈나이더, 베른하르트 시거 | ||||||||||||||||
| 빅 O 표기의 시간 복잡도 | |||||||||||||||||
| |||||||||||||||||
데이터 처리에서 R*-tree는 공간 정보를 인덱싱하기 위해 사용되는 R-tree의 변형입니다.데이터를 재삽입해야 하므로 R*Tree는 표준 R-Tree보다 다소 높은 구축 비용을 갖습니다.그러나 일반적으로 결과 트리의 쿼리 성능이 향상됩니다.표준 R-트리와 마찬가지로 포인트 및 공간 데이터를 모두 저장할 수 있습니다.이것은 1990년에 [1]노르베르트 베크만, 한스-피터 크리겔, 랄프 슈나이더, 그리고 베른하르트 시거에 의해 제안되었다.
R* 트리와 R-tree의 차이

커버리지와 오버랩을 최소화하는 것은 R-트리의 성능에 매우 중요합니다.오버랩은 데이터 쿼리 또는 삽입 시 트리의 여러 분기를 확장해야 함을 의미합니다(중복될 수 있는 영역에서 데이터가 분할되는 방식 때문에).커버리지를 최소화하면 프루닝 성능이 향상되므로 특히 음의 범위 쿼리의 경우 전체 페이지를 검색에서 더 자주 제외할 수 있습니다.R*트리는 수정된 노드 분할 알고리즘과 노드 오버플로 시 강제 재삽입 개념을 조합하여 둘 다 줄이려고 합니다.이는 R-트리 구조가 엔트리가 삽입되는 순서에 매우 민감하기 때문에 (벌크 로딩이 아닌) 삽입 빌드된 구조가 최적이 아닐 수 있다는 관찰에 기초하고 있습니다.항목을 삭제하고 다시 삽입하면 트리에서 원래 위치보다 더 적합한 위치를 "찾을" 수 있습니다.
노드가 오버플로우하면 엔트리의 일부가 노드에서 삭제되어 트리에 다시 삽입됩니다.(그 후의 노드 오버플로에 의한 무한 캐스케이드 재삽입을 피하기 위해 새로운 엔트리를 삽입할 때 트리의 각 레벨에서 재삽입 루틴을 1회만 호출할 수 있습니다).이로 인해 노드 내에 보다 적절하게 클러스터된 엔트리 그룹이 생성되어 노드의 커버리지가 감소합니다.또한 실제 노드 분할이 연기되는 경우가 많아 평균 노드 점유율이 상승합니다.재삽입은 노드 오버플로우 시 트리거되는 증분 트리 최적화 방법으로 볼 수 있습니다.
성능
- 향상된 분할 경험적 접근법은 보다 직사각형으로 페이지를 생성하므로 많은 응용 프로그램에 적합합니다.
- 재삽입 방식은 기존 트리를 최적화하지만 복잡성이 증가합니다.
- 점과 공간 데이터를 동시에 효율적으로 지원합니다.

Guttman 2차 [2]분할이 있는 R-트리.
독일 전역에는 동서로 뻗은 페이지가 많고 겹치는 페이지도 많다.이는 많은 슬라이스와 교차하는 작은 직사각형 영역만 필요로 하는 대부분의 응용 프로그램에는 적합하지 않습니다.
Ang-Tan 선형 분할이 있는 [3]R-Tree.
슬라이스가 Guttman까지 확장되지는 않지만 슬라이스 문제는 거의 모든 리프 페이지에 영향을 미칩니다.리프 페이지는 거의 겹치지 않지만 디렉토리 페이지는 겹칩니다.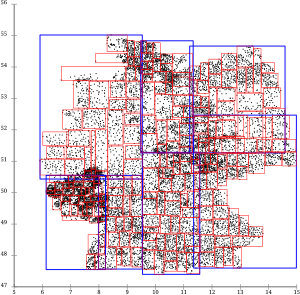
R* 트리 토폴로지 [1]분할
R* 트리는 페이지 오버랩을 최소화하려고 하기 때문에 페이지 오버랩은 거의 없습니다.또한 재삽입에 의해 트리가 더욱 최적화되었습니다.분할 전략도 슬라이스를 선호하지 않기 때문에 결과 페이지는 일반적인 지도 어플리케이션에서 훨씬 유용합니다.



알고리즘과 복잡성
- R* 트리는 쿼리 및 삭제 조작에 일반 R 트리와 동일한 알고리즘을 사용합니다.
- 삽입 시 R* 트리는 복합 전략을 사용합니다.리프 노드의 경우 오버랩이 최소화되고 내부 노드의 경우 확대 및 면적이 최소화됩니다.
- 분할 시 R* 트리는 둘레에 따라 분할 축을 선택한 다음 중첩을 최소화하는 위상 분할을 사용합니다.
- 스플릿 전략의 향상과 더불어 R*트리는 오브젝트와 서브트리를 트리에 재삽입함으로써 스플릿을 회피하려고 합니다.이는 B-트리의 밸런스 개념에서 착안한 것입니다.
따라서 최악의 경우 쿼리와 삭제 복잡도는 R-Tree와 동일합니다.R*트리에 대한 삽입 전략은 O logM에 것입니다.OM는 R-트리의 선형 분할 전략(보다 복잡하지만 2차 분할 전략(보다는 복잡하지 않습니다.페이지 크기는M개(\ M이며 전체 복잡성에는 거의 영향을 미치지 않습니다.전체 삽입 복잡도는 여전히 R-트리와 비슷합니다.재삽입은 트리의 최대 1개의 브랜치에 영향을 .따라서 O n) style(\displaystyle {n)) 재삽입은 일반 R-트리에서 스플릿을 실행하는 것과 비슷합니다.따라서 전반적으로 R* 트리의 복잡성은 일반 R 트리와 동일합니다.

 R-트리의 선형 분할 전략(
R-트리의 선형 분할 전략( 전체 복잡성에는 거의 영향을 미치지 않습니다.전체 삽입 복잡도는 여전히 R-트리와 비슷합니다.재삽입은 트리의 최대 1개의 브랜치에 영향을
전체 복잡성에는 거의 영향을 미치지 않습니다.전체 삽입 복잡도는 여전히 R-트리와 비슷합니다.재삽입은 트리의 최대 1개의 브랜치에 영향을 
완전한 알고리즘의 실장에서는, 여기서 설명하지 않는 많은 코너 케이스와 넥타이 상황에 대처할 필요가 있습니다.
레퍼런스
- ^ a b Beckmann, N.; Kriegel, H. P.; Schneider, R.; Seeger, B. (1990). "The R*-tree: an efficient and robust access method for points and rectangles". Proceedings of the 1990 ACM SIGMOD international conference on Management of data - SIGMOD '90 (PDF). p. 322. doi:10.1145/93597.98741. ISBN 0897913655.
- ^ Guttman, A. (1984). "R-Trees: A Dynamic Index Structure for Spatial Searching". Proceedings of the 1984 ACM SIGMOD international conference on Management of data - SIGMOD '84 (PDF). p. 47. doi:10.1145/602259.602266. ISBN 0897911288.
- ^ Ang, C. H.; Tan, T. C. (1997). "New linear node splitting algorithm for R-trees". In Scholl, Michel; Voisard, Agnès (eds.). Proceedings of the 5th International Symposium on Advances in Spatial Databases (SSD '97), Berlin, Germany, July 15–18, 1997. Lecture Notes in Computer Science. Vol. 1262. Springer. pp. 337–349. doi:10.1007/3-540-63238-7_38.

