두 데이터 군집 사이의 유사성 측정
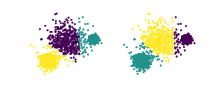
kMeans(왼쪽) 및 Mean shift(오른쪽) 알고리즘을 사용하는 데이터 집합의 클러스터링 예이 두 군집에 대해 계산된 조정된 랜드 지수는 A R I . 약 0.이다. 통계, 특히 데이터 클러스터링에서 랜드 지수[1] 또는 랜드 측정(William M. Rand의 이름)은 두 데이터 클러스터링 사이의 유사성을 측정하는 척도다.요소의 우연한 그룹화에 따라 조정되는 랜드 지수의 형태를 정의할 수 있는데, 이것이 수정된 랜드 지수다.수학적인 관점에서 랜드 지수는 정확도와 관련이 있지만 클래스 라벨을 사용하지 않을 때에도 적용된다.
랜드 지수
정의
Given a set of  elements
elements  and two partitions of
and two partitions of  to compare,
to compare,  , a partition of S into r subsets, and s 하위 에 대한 S의 displaystyle Y=\{Y_1
, a partition of S into r subsets, and s 하위 에 대한 S의 displaystyle Y=\{Y_1 }\}}}을(를) 정의하십시오.
}\}}}을(를) 정의하십시오.
-
 X의
X의 동일한 부분 집합과 의 동일한 부분 집합에 있는 의 요소 쌍 수
동일한 부분 집합과 의 동일한 부분 집합에 있는 의 요소 쌍 수 -
 X X의 서로 다른 하위 집합과 Y 의 서로 다른 하위 집합에 있는 의 요소 쌍 수
X X의 서로 다른 하위 집합과 Y 의 서로 다른 하위 집합에 있는 의 요소 쌍 수 -
 X의 동일한 부분 집합과 Y 의 다른 부분 집합에 있는 의 요소 쌍 수
X의 동일한 부분 집합과 Y 의 다른 부분 집합에 있는 의 요소 쌍 수 -
 의 서로 다른 하위 집합과 의 동일한 하위 집합에 있는 의 요소 쌍 수
의 서로 다른 하위 집합과 의 동일한 하위 집합에 있는 의 요소 쌍 수
랜드 지수 R}은 는) 다음과 같다.[1][2]
는) 다음과 같다.[1][2]

으로+ 을(를) 과(와) 과( ) + 사이의
) + 사이의 합의 수로 간주할 수 있다
합의 수로 간주할 수 있다
분모가 전체 쌍의 수이기 때문에 랜드 지수는 전체 쌍에 대한 합의의 발생 빈도 또는 임의로 선택한 쌍에 대해 X과 이(가) 합의할 확률을 나타낸다.
) 2은(는) ()/ 로 계산된다

마찬가지로 랜드 지수도 알고리즘에 의해 이루어진 올바른 결정의 비율의 척도로 볼 수 있다.다음 공식을 사용하여 계산할 수 있다.

- 서 T 은
 (는) 참 양수, N 은
(는) 참 양수, N 은 참 음수, 은
참 음수, 은
 거짓 양수다.
거짓 양수다.
특성.
랜드 지수는 0과 1 사이의 값을 가지며, 0은 두 데이터 군집이 어떤 점 쌍에도 일치하지 않음을 나타내고 1은 데이터 군집화가 정확히 동일함을 나타낸다.
수학적 용어로 a, b, c, d는 다음과 같이 정의된다.
 , where
, where 
 , where
, where 
 , where
, where 
 , where
, where 
for some 
분류 정확도와 관계
랜드 인덱스는 S 의 요소 쌍에 대한 이진 분류 정확도의 프리즘을 통해 볼 수 있다 두 클래스 라벨은 " i }이고 j 는 및 와 "에서 동일한 하위 집합에 있다
i }이고 j 는 및 와 "에서 동일한 하위 집합에 있다 . 와 는 와 Y Y의 다른 하위 집합에 있다.
. 와 는 와 Y Y의 다른 하위 집합에 있다.
이 설정에서 은(는) 동일한 하위 집합(참의 양)에 속하는 것으로 올바르게 표시된 쌍의 수이며, b 은 다른 하위 집합(참의 음)에 속하는 것으로 올바르게 표시된 쌍의 수입니다.
조정 랜드 지수
수정된 랜드 지수는 랜드 지수의 보정 버전이다.[1][2][3]그러한 우연에 대한 보정은 무작위 모델에 의해 지정된 군집들 간의 모든 쌍-현상 비교의 예상 유사성을 이용하여 기준선을 설정한다.전통적으로, 랜드 지수는 클러스터링에 대한 순열화 모델(클러스터 내의 클러스터 수와 크기는 고정되어 있으며, 모든 랜덤 클러스터링은 고정 클러스터 간에 요소를 섞어서 생성된다.)을 사용하여 수정되었다.그러나 순열모형의 전제는 자주 위반된다. 많은 클러스터링 시나리오에서 군집의 수나 군집의 크기 분포는 크게 다르다.예를 들어, K-평균에서 군집 수는 실무자에 의해 고정되지만 군집 크기는 데이터에서 유추된다는 점을 고려하십시오.조정된 랜드 인덱스의 변동은 랜덤 클러스터링의 다른 모델을 설명한다.[4]
랜드 지수는 0에서 +1 사이의 값만 산출할 수 있지만, 랜드 지수가 기대 지수보다 작을 경우 수정된 랜드 지수는 음의 값을 산출할 수 있다.[5]
분할표
Given a set S of n elements, and two groupings or partitions (e.g. clusterings) of these elements, namely  and
and  , the overlap between X and Y can be summarized in a contingency table
, the overlap between X and Y can be summarized in a contingency table ![\left[n_{ij}\right]](https://wikimedia.org/api/rest_v1/media/math/render/svg/cf6d61cf9a2d775ae845160965e9e62ca6e038d3) where each entry
where each entry  denotes the number of objects in common between
denotes the number of objects in common between  and
and  : }
: } .
.

정의
순열모형을 이용한 원래의 조정된 랜드지수는
![{\displaystyle ARI={\frac {\left.\sum _{ij}{\binom {n_{ij}}{2}}-\left[\sum _{i}{\binom {a_{i}}{2}}\sum _{j}{\binom {b_{j}}{2}}\right]\right/{\binom {n}{2}}}{\left.{\frac {1}{2}}\left[\sum _{i}{\binom {a_{i}}{2}}+\sum _{j}{\binom {b_{j}}{2}}\right]-\left[\sum _{i}{\binom {a_{i}}{2}}\sum _{j}{\binom {b_{j}}{2}}\right]\right/{\binom {n}{2}}}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/9e0f6f21c547bd71629352a4b543119f6822d7ad)
여기서 , 은 분할표의 값이다 .
.
참고 항목
참조
외부 링크



