린들리의 역설
Lindley's paradox린들리의 역설은 베이지안인과 단골주의자가 가설시험 문제에 접근하는 통계에서 이전 분포의 특정 선택에 대해 서로 다른 결과를 주는 반직관적 상황이다.두 접근법 사이의 의견 불일치의 문제는 해롤드 제프리스의 1939년 교과서에서 논의되었다;[1] 그것은 데니스 린들리가 1957년 논문에서 의견 불일치를 역설이라고 말한 이후 린들리의 역설로 알려지게 되었다.[2]
역설이라고 일컬어지지만 베이시안적 접근법과 빈번한 접근법의 다른 결과는 두 방법 사이의 실제적인 의견 불일치보다는 근본적으로 다른 질문에 답하기 위해 그것들을 이용하는 것으로 설명할 수 있다.
그럼에도 불구하고, 많은 종류의 선행학자들의 경우, 빈도수론자와 베이지안 접근법의 차이는 유의 수준을 고정시킨 것에 의해 야기된다: 린들리가 인식한 대로, "이 이론은 유의 수준을 고정시키는 관행을 정당화하지 못한다" 그리고 심지어 "교수님의 일부 계산"까지.피어슨은 토론에서 종이를 유의 수준 만약 상실 및 사전 확률을 고정된 계속되었던 샘플 파일로 변경할 수 있는 것이라고 강조했다.샘플 크기와 함께 가장 중요한 값 인상 적절하게 빨리"[2]사실이 frequentist과 베이즈의 접근법 간의 차이에 무시해도 될 정도로 된다.e 표본 크기가 증가한다.[3]
역설 설명
일부 실험의 x 에는 가설 및 H }의 두 가지 가능한 설명이 있으며 어떤 가설이 더 ac적인지 불확실성을 나타내는 일부 사전 분포 \textstyle . 을(를) 고려하기 전에 큐레이팅하십시오




린들리의 역설은
- 결과 은(는) 의 빈도리스트 테스트에 의해 "중대한"이며 이는 예를 들어 5% 수준에서 거부하기에 충분한 증거를 나타낸다.
- 가주어진H 0 {\ \ 의 후방 확률은 , H {H 1x x}와 더 잘 일치한다는 강한 증거를 나타낸다
이러한 결과는 H 이(가) 매우 구체적이고, 1 {\ \textstyle 이(가) 더 분산되어 있을 때 동시에 발생할 수 있으며, 이전 분포는 아래와 같이 한쪽을 강하게 선호하지 않는다.
숫자 예제
다음의 수치적 예는 린들리의 역설을 예시하고 있다.특정 도시에서 남자 49,581명과 여자 48,870명이 특정 기간 동안 태어났다.따라서 남성 출산의 관측된 x 은 49,581/98,451 ≈ 0.5036이다.우리는 남성 출산의 분율이 매개 변수 }을를) 가진 이항 변수라고 가정한다 우리는 이(가) 0.5인지 아니면 다른 값인지 테스트하는 데 관심이 있다.즉, 우리의 귀무 가설은 := 0.5 = 0.5이고 대안은 H : 0.5 0.5

 대안은 H
대안은 H 
단골접근법
을(를) 테스트하는 빈도수주의적 접근방식은 p-값을 계산하는 것으로, 이 참이라고 가정할 때 x 만큼의 남아를 관측할 확률이다.Because the number of births is very large, we can use a normal approximation for the fraction of male births , with and -)= .5 = {\ \textstyle ^{2 ( 0.5을 계산하기 위해 .




We would have been equally surprised if we had seen 49,581 female births, i.e. , so a frequentist would usually perform a two-sided test, for which the p-value would be . In both cases, the p-value는 5%의 유의 수준 α보다 낮기 때문에 빈도주의 접근방식은 0 관측 데이터에 동의하지 않으므로 거부한다.


베이시안 어프로치
Assuming no reason to favor one hypothesis over the other, the Bayesian approach would be to assign prior probabilities and a uniform distribution to under , and then 베이즈의 정리를 이용하여 의 후확률을 계산한다.



= n = 출생아 중 남자아이를 관찰한 후 이항 변수에 대한 확률 질량 함수를 사용하여 각 가설의 후확률을 계산할 수 있다.



서 B( , )B은 베타 함수다.
 베타
베타 이러한 값들로부터 는 H 의 후행 확률을 수 있는데 이는 H 1 {\displaystyle 보다 H }}}}}을 강하게 선호한다

베이시안과 빈도수주의자인 두 사람이 대립하고 있는 것으로 보이며, 이것이 바로 '파라독스'이다.
베이시안적 접근 방식과 빈번한 접근 방식 조정
그러나 적어도 린들리의 예에서 유의수준의 순서를 따지면 α = n과−r 같은 αnn = r > 1/2로 합치면 null의 후확률이 0으로 수렴되어 null의 거부반응과 일치한다.[3]이 수치의 예에서 r = 1/2을 취하면 유의 수준이 0.00318이므로 빈도주의자는 대략 베이지안 접근방식과 일치하는 귀무 가설을 거부하지 않을 것이다.
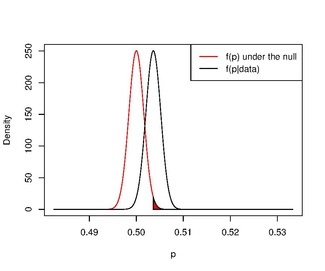
만약 우리가 비정보적 전제를 사용하고 빈번한 접근법에서 그것과 더 유사한 가설을 시험한다면, 역설은 사라진다.
For example, if we calculate the posterior distribution , using a uniform prior distribution on (i.e. ), we find

![\textstyle \pi(\theta \in [0,1]) = 1](https://wikimedia.org/api/rest_v1/media/math/render/svg/755f6338d2d6c0f581f1af23bb772dd9dd2acadc)

이것을 이용하여 여자아이보다 남자아이가 될 확률이 높은지, 즉 (> .5 , n P k 우리는 이것을 발견한다


즉, 남성 출생아 비율이 0.5를 넘을 가능성이 매우 높다.
두 분석 모두 직접 효과 크기에 대한 추정치를 제공하지는 않지만, 예를 들어, 남아 출생 비율이 특정 임계값을 초과할 가능성이 높은지를 결정하는 데 둘 다 사용될 수 있다.
실제 역설의 결여
두 접근법 사이의 명백한 불일치는 요인의 조합에 의해 야기된다.먼저 위의 은 H 1 {\ \H_{0}을 참조하지 않고 H 0 베이시안 접근방식은 \을(를 1 {\ \textstyle }의 대안으로 평가한 후 관측치와 더 잘 일치하는 첫 번째 항목을 찾는다.이는 후자의 가설이 훨씬 더 확산되기 때문인데 이는 이(가 [ ] 의 어느 곳에나 있을 수 있기 때문에 후자의 가설이 매우 낮은 후자의 확률을 가질 수 있기 때문이다.그 이유를 이해하려면 두 가지 가설을 관측치의 생성자로 간주하는 것이 도움이 된다.
![\textstyle [0, 1]](https://wikimedia.org/api/rest_v1/media/math/render/svg/bbfdf72e3d8918aa908f51a9d4b5ed68bea1bc0b)
- 아래에서 00을 선택하고 98,451명의 출생아 중 49,581명의 남자아이를 볼 가능성이 있는지 물어본다.
- } 아래에서 0 ~ 1 내의 임의로 {\을 선택하고 동일한 질문을 한다

\textstyle } 아래의 displaystyle \ \에 대해 가능한 대부분의 값은 관측치에 의해 매우 낮은 지지를 받고 있다.본질적으로 방법들 간의 명백한 불일치는 전혀 불일치가 아니라 가설들이 데이터와 어떻게 관련되어 있는지에 대한 두 가지 다른 진술이다.
- 단골손님은 H 이 관찰에 대한 좋지 않은 설명임을 알게 된다.
- Bayesian은 H 이(가) 1 \}보다 관찰에 대한 설명이 훨씬 낫다는 것을 발견했다
신생아 성별 비율은 아마도 남성/여성 50/50일 것이다.그러나 50/50은 대부분의 다른 비율보다 더 나은 근사치지만 전부는 아니다.가설0. \textstyle \ \theet \\theet \약 0.은(는 .을 포함한 거의 모든 비율보다 관측치에 훨씬 잘 적합할 것이다

예를 들어, 가정 및 이전 가능성의 이 선택은 성명:"만약 θ{\displaystyle \textstyle \theta}>0.49과 θ{\displaystyle \textstyle \theta}<>0.51, 그때 θ의 사전 확률{\displaystyle \theta}고 정확히 0.5는 0.50/0.51 ≈{\displaystyle \approx}98%이다."을 감안할 때를 암시한다.그러한a strong preference for , it is easy to see why the Bayesian approach favors in the face of , even though the observed value of lies away from 0.5.H 에서 2 시그마 이상의 편차는 빈도론적 접근방식에서 유의한 것으로 간주되지만, 베이시안 접근방식에서 그 중요성은 이전 접근방법에 의해 무시된다.





다른 방식으로 보면, 이전 분포가 근본적으로 평평하며 델타 함수가 = 0.= 0.5인 것을 알 수 있다 분명히 이것은 의심스럽다.실제로 실수를 연속된 숫자로 나타낸다면, 주어진 숫자가 정확히 매개변수 값일 수 없다고 가정하는 것이 더 논리적일 것이다. , P=.5)= 을 가정해야 한다


대립 가설에서 \에 대한 보다 현실적인 분포는 의 후면에 대해 덜 놀라운 결과를 산출한다 예를 들어, 로 H 1{1}{{{{{{{{{{{{{{{{{{{{{{{ = = xxplaystyplayst, i.e., the maximum likelihood estimate for , the posterior probability of would be only 0.07 compared to 0.93 for (Of course, one cannot actually use the MLE as part of a prior dis공로


최근 토론
그 역설은 계속 활발한 토론의 원천이 되고 있다.[3][4][5][6]
참고 항목
메모들
- ^ Jeffreys, Harold (1939). Theory of Probability. Oxford University Press. MR 0000924.
- ^ a b Lindley, D.V. (1957). "A statistical paradox". Biometrika. 44 (1–2): 187–192. doi:10.1093/biomet/44.1-2.187. JSTOR 2333251.
- ^ a b c Naaman, Michael (2016-01-01). "Almost sure hypothesis testing and a resolution of the Jeffreys-Lindley paradox". Electronic Journal of Statistics. 10 (1): 1526–1550. doi:10.1214/16-EJS1146. ISSN 1935-7524.
- ^ Spanos, Aris (2013). "Who should be afraid of the Jeffreys-Lindley paradox?". Philosophy of Science. 80.1: 73–93. doi:10.1086/668875.
- ^ Sprenger, Jan (2013). "Testing a precise null hypothesis: The case of Lindley's paradox" (PDF). Philosophy of Science. 80: 733–744. doi:10.1086/673730. hdl:2318/1657960.
- ^ Robert, Christian P. (2014). "On the Jeffreys-Lindley paradox". Philosophy of Science. 81.2: 216–232. arXiv:1303.5973. doi:10.1086/675729.
추가 읽기
- Shafer, Glenn (1982). "Lindley's paradox". Journal of the American Statistical Association. 77 (378): 325–334. doi:10.2307/2287244. JSTOR 2287244. MR 0664677.

