렘펠-지브 복잡도
Lempel–Ziv complexity렘펠-지브 복잡도는 유한 시퀀스의 복잡성(IEEE Trans) 기사에서 처음 제시된 척도이다.IT-22,11976년)에 대해서, Abraham Lempel과 Jacob Ziv라는 두 명의 이스라엘 컴퓨터 과학자에 의해서.이 복잡도 척도는 Kolmogorov 복잡도와 관련이 있지만 사용하는 함수는 재귀 복사(즉, 얕은 복사)뿐입니다.
이 복잡도 측정의 기초가 되는 메커니즘은 LZ77, LZ78 및 LZW와 같은 무손실 데이터 압축 알고리즘의 시작점입니다.단어 복사의 기본 원리에 기초하고 있지만, 이 복잡도 측정은 그러한 측정이 기대하는 주요 특성을 충족한다는 점에서 그다지 제한적이지 않다. 즉, 일정한 규칙성을 가진 시퀀스는 너무 큰 복잡도를 가지지 않으며, 시퀀스의 길이와 불규칙성이 증가함에 따라 복잡도가 증가한다.
렘펠-지브 복잡도는 노래 가사나 산문과 같은 이진 시퀀스와 텍스트의 반복성을 측정하는 데 사용할 수 있습니다.실제 데이터의 프랙탈 차원 추정치는 렘펠-지브 [1][2]복잡성과도 관련이 있는 것으로 나타났다.
원칙
S를 길이 n의 2진수열이라고 하자. 여기서 우리는 C(S)로 표기된 렘펠-지브 복잡도를 계산해야 한다.순서는 왼쪽부터 읽습니다.
계산 중에 순차적으로 이동할 수 있는 구분선이 있다고 가정합니다.처음에 이 행은 첫 번째 심볼 바로 뒤에 시퀀스 시작 부분에서 설정됩니다.이 초기 위치를 위치 1이라고 하며, 여기서 위치 2로 이동해야 하며, 다음 단계(등)의 초기 위치로 간주됩니다.딜리미터의 위치 1과 딜리미터 위치 사이의 하위 단어가 딜리미터의 위치 1보다 먼저 시작되는 시퀀스의 단어가 되도록 딜리미터(위치 1)를 더 오른쪽으로 이동해야 합니다.
딜리미터가 이 조건이 충족되지 않는 위치에 설정되는 즉시 중지하고 딜리미터를 이 위치로 이동한 다음 이 위치를 새 초기 위치(즉, 위치 1)로 표시하여 다시 시작합니다.시퀀스가 끝날 때까지 계속 반복합니다.Lempel-Ziv 복잡도는 이 절차를 완료하는 데 필요한 반복 횟수에 해당합니다.
다르게 말하면, 렘펠-지브 복잡도는 이진수열(왼쪽에서 오른쪽으로)을 스트림으로 볼 때 발생하는 서로 다른 하위 문자열(또는 하위 단어)의 수입니다.
형식적인 설명
Lempel과 Ziv가 제안한 방법은 여기서 정의한 시퀀스의 재현성, 생산성 및 철저한 이력이라는 세 가지 개념을 사용합니다.
표기법
S를 길이 n(즉, 값 0 또는 1을 갖는 n개의 기호)의 이진수열이라고 하자.S(i,j)는 1 1i, n로 인덱스 i에서 인덱스 j(j<i,S(i,j)가 빈 문자열인 경우)까지의 S의 서브워드로 합니다.S의 길이 n은 l(S)로 나타나며 시퀀스 Q는 다음과 같은 경우 S의 고정 프레픽스라고 불립니다.


재현성과 생산성

한편, 길이 n의 시퀀스 S는, S(j+1, n)가 S(1, j)의 서브워드인 경우, 그 프리픽스 S(1, j)로부터 재현 가능하다고 한다.이것은 S(1,j)→S로 표기된다.
이와 달리 S는 나머지 시퀀스 S(j+1,n)가 다른 서브워드의 복사(S(1,n-1의 인덱스 i < j+1)에서 시작)에 지나지 않는 경우 프리픽스 S(1,j)로부터 재현할 수 있다.
시퀀스 S가 프리픽스 S(1,j) 중 하나로 재현될 수 있음을 증명하려면 다음 사항을 제시해야 합니다.


한편, 생산성은 재현성으로부터 정의된다.S(1,n-1)가 S(1,j)로부터 재현 가능한 경우, 시퀀스 S는 프리픽스 S(1,j)로부터 생성 가능하다.이것은 S(1,j)s S로 표시됩니다.이와 달리 S(j+1,n-1)는 S(1,n-2)의 다른 서브워드의 복사본이어야 한다.S의 마지막 기호는 새로운 기호일 수 있으며(그러나 그럴 수 없음), 새로운 하위 단어가 생성될 수 있다(따라서 생산가능성이라는 용어).

철저한 이력 및 복잡성
생산성의 정의에서 빈 문자열 δ=S(1,0) δS(1,1)따라서 재귀 생성 프로세스에 의해 스텝 i에서는 S(1, hi) s S(1, hi+1)를 얻을 수 있기 때문에 S를 프리픽스로 만들 수 있습니다.그리고 S(1,i) s S(1,i+1) (hi+1=hi+1)는 항상 참이므로, 이 S의 제조 공정은 최대 n=l(S) 단계로 이루어진다.Let m, , be the number of steps necessary for this product process of S. S can be written in a decomposed form, called history of S, and denoted H(S), defined like this:



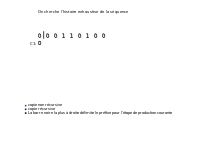
S의 성분 Hi(S)는 S(1, hi)가 S(1, hi-1)(즉 S(1, hi-1) s S(1, hi-1)가 S(1, hi-1)를 생성하지 않고 S(1, hi-1)에 의해 생성된 가장 긴 배열인 경우, S(1, hi-1)의 성분 Hi(S)는 완전하다고 한다.( , - )S ( , S (, _ { }- ( h _ { i )가장 긴 생산을 가능하게 하는 인덱스 p를 포인터라고 부릅니다.

S의 이력은 아마도 마지막 것을 제외하고 모든 성분이 완전하다면 완전하다고 한다.이 정의에서 시퀀스 S는 하나의 완전한 이력만을 가지며, 이력은 가능한 모든 S의 이력 중 가장 적은 수의 성분을 가진 것임을 알 수 있다.마지막으로, 이러한 S의 고유한 완전 이력의 성분 수를 S의 렘펠-지브 복잡도라고 한다.
알고리즘.
다행히, 이 복잡도를 계산하는 매우 효율적인 방법이 수열 S의 n (\ n = l n = l (S)}에 O( style {)\displaystyle n(Sdisplaystyle {O})}(n})에 한다


이 방법에 대한 공식적인 설명은 다음 알고리즘에 의해 제공됩니다.
- i = p - 1, p는 포인터입니다(위 참조).
- u는 현재 프리픽스의 길이입니다.
- v는 현재 포인터 p의 현재 컴포넌트 길이입니다.
- vmax는 현재 컴포넌트에 사용되는 최종 길이입니다(가능한 모든 포인터에서 가장 큼).
- C는 반복적으로 증가하는 렘펠-지브 복잡도이다.
// S는 크기 n의 이진 시퀀스입니다. i := 0 C := 1 u := 1 v := 1 VMAX := v 하는 동안에 u + v <=> n 하다 한다면 S[i + v] = S[u + v] 그리고나서 v := v + 1 또 다른 VMAX := 맥스.(v, VMAX) i := i + 1 한다면 i = u 그리고나서 // 모든 포인터가 처리되었습니다. C := C + 1 u := u + VMAX v := 1 i := 0 VMAX := v 또 다른 v := 1 끝. 한다면 끝. 한다면 끝. 하는 동안에 한다면 v != 1 그리고나서 C := C+1 끝. 한다면 「 」를 참조해 주세요.
주 및 참고 자료
레퍼런스
- ^ Burns, T.; Rajan, R. (2015). "Burns & Rajan (2015) Combining complexity measures of EEG data: multiplying measures reveal previously hidden information. F1000Research. 4:137". F1000Research. 4: 137. doi:10.12688/f1000research.6590.1. PMC 4648221. PMID 26594331.
- ^ Burns, T.; Rajan, R. (2019). "A Mathematical Approach to Correlating Objective Spectro-Temporal Features of Non-linguistic Sounds With Their Subjective Perceptions in Humans". Frontiers in Neuroscience. 13: 794. doi:10.3389/fnins.2019.00794. PMC 6685481. PMID 31417350.
참고 문헌
- Abraham Lempel과 Jacob Ziv, 『유한 시퀀스의 복잡성에 대하여』, IEEE Trans.정보이론에 대하여, 1976년 1월, 75-81, vol. 22, n°1
어플
- Pop Loss Getting More Repeative?By Colin Morris는 Lempel-Ziv 복잡도를 사용하여 노래 가사의 반복성을 측정하는 방법을 설명하는 블로그 게시물입니다(소스 코드 사용 가능).
- Burns & Rajan (2015) EEG 데이터의 복잡성 측정치를 조합하여 측정치를 곱하면 이전에 숨겨진 정보가 드러난다.F1000 Research. 4:137. [1] (공용 MATLAB 코드 사용 가능).
- Burns & Rajan(2019) 비언어적 소리의 객관적 스펙트럼-일시적 특징을 인간의 주관적 인식과 상관시키는 수학적 접근법.신경과학 분야 개척자 13장 794절.[2] (공개 MATLAB 코드 사용 가능).



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}